Home
This wiki is targeted at developers contributing to this project. Here one will find a break down of project internals: classes used, file structure and similar information.
Pre-configured debugging configurations for VSCode come with the project.
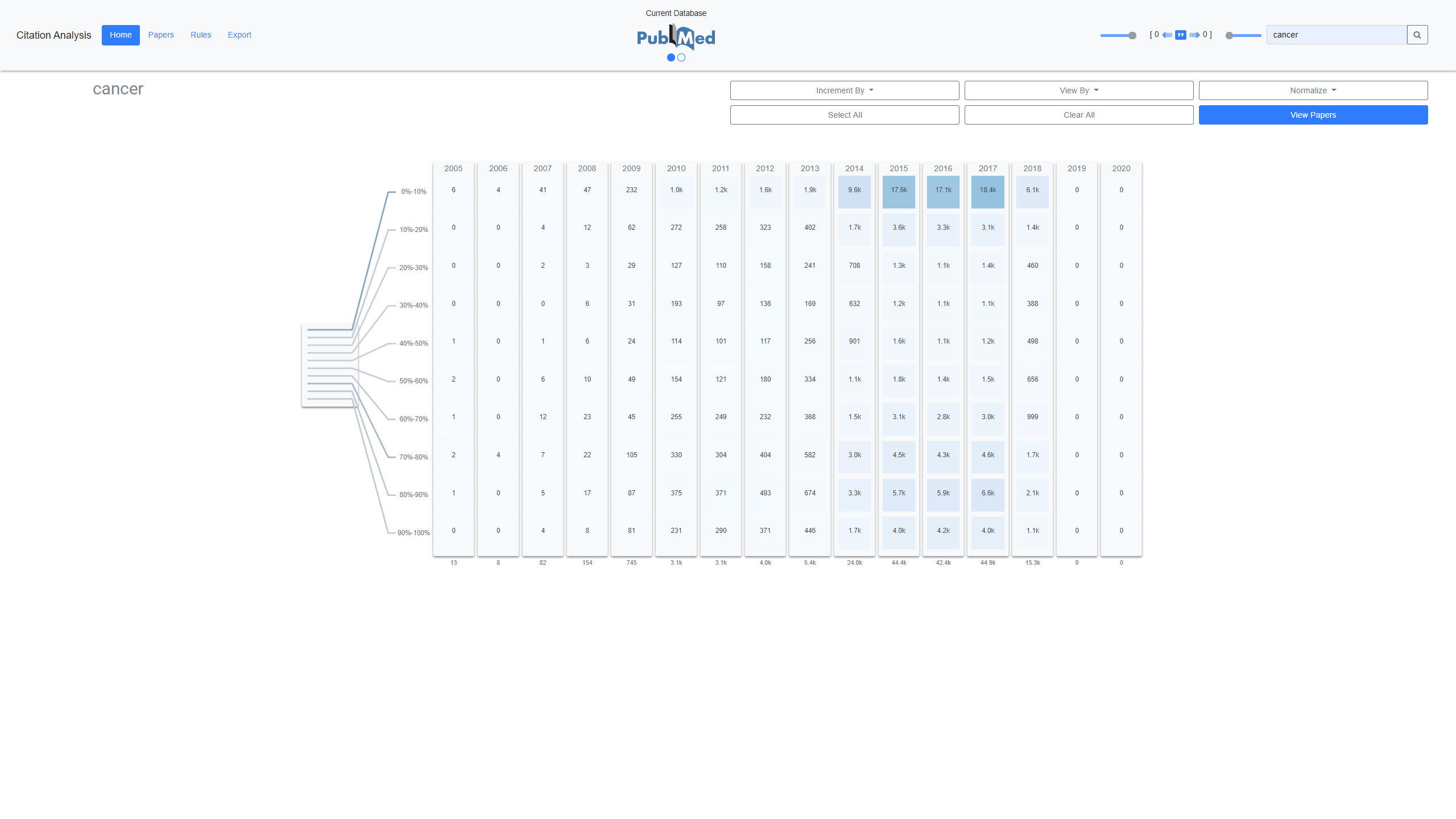
Citation Galaxy objective is to provide a text analysis tool specifically geared to aid in Bibliometrician's work. Their work surrounds how, where, and when citations occur in academic texts. Traditionally they use python and various text parsing scripts to accomplish their goals. Citation Galaxy is designed to be a visual application that the user can easily interact with the UI and produce complex "rules". The rules allow the user to create logical gates that the backend will use to find occurences of the rule in the Pubmed corpus. For example, a simple rule can be a term such as heart and a range which denotes how far away the term heart must be from a citation. The range is based off sentences for example if the rule is 0<- heart ->0, the term heart must occur within a sentence that also contains a citation.
node
The node folder is your working directory for the project
-
backend
The backend folder is your Node.js server codeindex.js
Main FileThis file sets up all the routing, dotEnv, middleware (express-session), and Socket.IO.
Notable Info:
- SocketManager is used for two way communications to update progress bars.
- Express-Session is stored in the Postgres DB, it is not located in memory. Do not change that because it is necessary for horizontal scaling.
- Post Body is set to 50MB, we ran into issues with maxing out get param limit. Should you run into that issue convert your get request to post.
userRoutes.js
This file contains all of the user routes
Notable Info:
- Creation of user uses email verfication
- Unverified Users have their own table, if a bug happens in the verification process you will have to fix the unverified table
- Recommend to use pool.query instead of creating specific clients
api.js
This file contains all of the api routes
Notable Info:
- Heavy dependency on dataLayer.js
- Typical pattern for determining selected database is having the frontend send in a bool to state what database it wants to query (isPubmed)
- The DATA_LAYER is the singleton class to access the database
- If that project is being pushed for more horizontal scaling, decoupling the api routes and adding a business layer will make it extremely scalable
dataLayer.js
This file is responsible for interacting with the database.
Notable Info:
- There are three classes ExportData, Pubmed, Erudit
- ExportData is reponsible for exporting the results so the user can download them
- Pubmed and Erudit have the exact same function signatures in order to be interchangeable
- would be a good idea to add a businessLayer.js for extra separation of concern
-
frontend
js
front.js
This file is the legacy UI. It is still relevant in the current application.
Notable Info:
- The home page's code resides in this file
- This file is global
- The grid, erudit timeline and search code resides in this file
paper.js
This file contains all of the code for the paper view page.
Notable Info:
- The page could be prone to locks due to needing a huge amount of memory
- The filter only applies to the in focus tab
newfront.js
This file is the new UI code.
Notable Info:
- The page could be prone to locks due to needing a huge amount of memory
- The filter only applies to the in focus tab
manager.js
This file deals with all of the rule forms.
Notable Info:
- Legacy
- This file does a lot of appending html to the DOM
dbManager.js
This file is responsible for holding the different state each database needs. If more features are added you will have to put the new state inside this file.
Notable Info:
- isPubmed is a vital boolean to the frontend that resides in this file
tools
This folder contains all of the python scripts necessary to load in new data.
pubmed_data_loader.py
This file is responsible for loading data into the database
Notable Info:
- when call this script make sure to pass the path to the data

//front.js
prepContainers(); // this function is responsible for clearing the grid and prepping it for new data
drawAllYears(data): // this function is responsible for drawing the new data in the gridconst getGridVisualization = async (req, res);//This function can be used to get the grid view if you already have data in the user table (very useful for making new features) - const requiredInfo = { bins: {}, years: [], isPubmed: false };
const ruleSearch = async (req, res); //This is the rule search api which changes the grid and updates the user table const requireInfo = {bins: {}, years: [], isPubmed: false,};
const search = async function (req, res); //This is the search api which changes the grid and updates the user table const requireInfo = { rule: {}, bins: {}, years: [], term: "", isPubmed: false,};
//manager.js
loadData( table_name,
params,
draw_table = true,
callback = undefined,
new_load = true); //this function is called after the rule query is returned form the server. It calls populateTable.
populateTable(
signals,
name,
table,
links,
actions,
schema,
external_data,
aliases
); //This function is responsible for drawing the rule tables
showAddRow(); //this is the function that appends another set of rules to the rule tableconst deleteRuleSet = async (req, res);//deletes rulesets
const updateRuleSet = async (req, res);//updates rulesets
const addRuleSet = async (req, res);//add rule sets to user table
const loadRuleSets = async (req, res);//initial load of the rule sets
const updateRule = async (req, res);//update specific rules
const addRule = async (req, res);//add rules
const loadRules = async (req, res);//load rules initially
//front.js
searchForQuery(); //this is called when the basic search is clicked on the UI
ruleSearch(); //this is called when the rule search is clicked on the UI
//newfront.js
spinIconDb(); //this is called when the db icon is clicked. This sets the current database.
snapshot(); //this is called when the camera icon is clicked.
//dbManager.js
//this contains the current database state. It is where all of the front end differences for pubmed and erudit reside. For example, the citation icon in the range is used for pubmed while in Erudit a T icon is used.const ruleSearch = async (req, res);//searches the current database for the supplied rules (expected input: const requireInfo = { bins: {},years: [], isPubmed: false,};)
const search = async function (req, res);//searches the current database for the term and range that is specified (expected input: const requireInfo = { rule: {}, bins: {}, years: [], term: "", isPubmed: false,};)
const submitSnapshot = async (req, res); //takes the snapshot and puts it in the snapshot_log table (expected input: const requiredInfo = { selection: [], filters: [], img: "", info: {} }; )
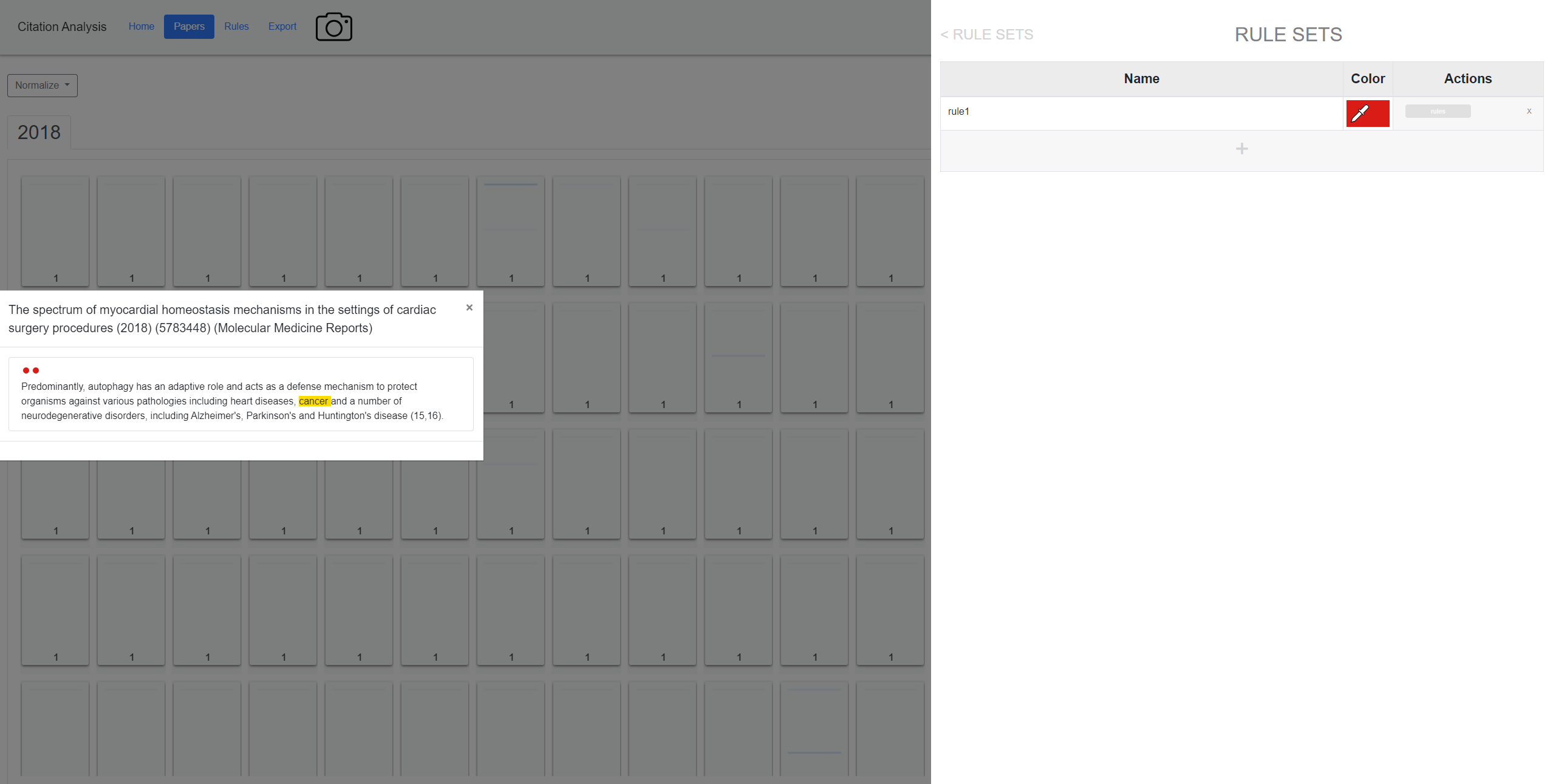
drawPaperList(
papers,
all_max,
sentenceHits,
ruleHits,
local_norm = false
);
drawPapersByIndex(results, local_norm = false);const getPapers = async (req, res); //gets the papers given the current selection in the grid view (expected input: const requiredInfo = { selections: [], rangeLeft: 0, rangeRight: 0, isPubmed: false,};)
const getPaper = async (req, res); //gets a specific paper, this is used when a user clicks a paper and the overlay pops up with all the information (expected input: let requiredInfo = { paper_id: 0, isPubmed: false };)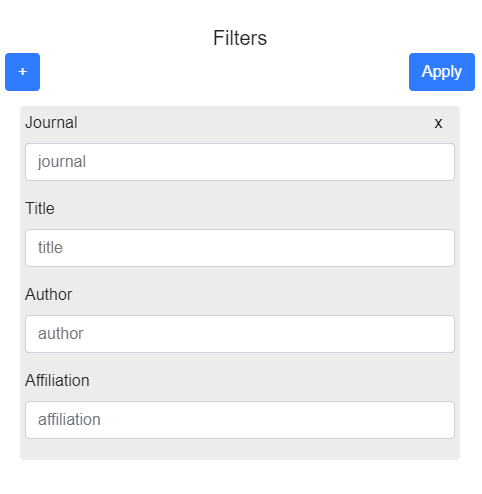
//newfront.js
submitFilters(); //called on submit, invokes getFilteredPapers()
addRowToFilterForm(); //called when filter is added
getFilterSuggestions(currentValue, filter, element); //called constantly when a filter field has new data. It is essentially the auto-complete
getFilteredPapers();//gets the data from the serverconst getFilterNames = async (req, res);//This function is used for auto-complete in the filter section of the paper view page (expected input: const requiredInfo = { filter: "", currentValue: "", ids: [], isPubmed: false, year: 0, }; )
const getFilteredIDs = async (req, res);//This function will give back the ids that meet the fields that are supplied (expected input: const requiredInfo = { fields: [], ids: [], isPubmed: false, year: 0 };) The pubmed data can be loaded in using pubmed_data_loader.py. The data loader requires a path to be specified when called.
[zhills@gpu04 Citation-Galaxies]$ nohup python -u pubmed_data_loader.py /Pubmed/non-commercial/ &It is important to make sure that the path points to either the commercial or non-commercial folder in the pubmed dataset. These folders exist in the bulk download of Pubmed. The nohup will ensure you can close the terminal and it will keep running. The & at the end flushes the output buffers to ensure the print functions and errors are being put into the nohup.out file. You can track the progress of the script in the nohup.out file.

It is important to note that the user id is constantly used with the snapshot logs and the user rules. The user id is stored in their session and is readily available in any api call through req.session.userId. The user passwords are encrypted using bcrypt it is extremely important not to change that. The tables that store the user's work is named after the user's id. For example, if Arthur's id is 3 his table would be user_temp_table_3.



The arrangement of the data in the tables is for a specific purpose of reducing overhead for calculations. The search query heavily relies on analyzing the data residing in the pubmed_text tables. By moving all of the pubmed_meta and pubmed_data into their own tables it requires significantly less overhead for the searches. The meta info is used specifically in the paper view page for filtering papers and displaying the meta information in the paper overlay. Furthermore, by separating the meta from the other data it is much easier to accomplish the task of filtering the papers and getting specific meta information with much less overhead. Lastly, the one caveat is when exporting the data everything has to be joined together and prepped to be downloaded. The way the database is currently setup it hinders the download process. One thing to look into in the future is some way of alleviating the overhead caused by exporting the data. The data is separated into year specific tables for the ability to use parallel processing to achieve better performance for the queries. I would highly recommend keeping the data separated into years.



The arrangement of the erudit data follows the exact same layout as Pubmed. Erudit does not need to be separated this way; however, it was done to ensure consistency between the two sets of data. If their is time the backend could be refactored to support erudit in a different database schema, although I am not sure what the benefit of that would be.
The first task is to create three new tables in the database: pubmed_meta_2021, pubmed_text_2021, pubmed_data_2021. The next step is to use the pubmed_data_loader.py and pass the directory that contains the new data in it. After the data has loaded in delete any records that don't have citations in it.
delete from pubmed_text_2021 where citations_full_text_sentences is null;Next go to statics.js and change the max_year.
//statics.js
const STATICS = {
YEAR_SPAN = { min_year: 2003, max_year: 2020 },
};Your new data is now available to be analyzed by users!
Due to Citation Galaxy having 3 separate major version the front end has had a lot of code changed/altered/removed or added. Currently, newfront.js is your safe haven to avoid the legacy code. Add your new code to newfront.js and initialize or add your hooks in the function setupEventHandlers().
The session data is stored on the Postgres database. The application was developed for horizontal scaling in mind in order for this project to actually have a full scale deployment utilizing technology like AWS. Therefore, the session data must be stored in the database in order to be sync to all of the node applications in the horizontal axis. In the current deployment at the university there is 4 node.js apps running for this project.
The session currently contains the user's session.id which is their unique session id, their email, their user id in the database, and their socketId which is responsible for two way communication with the client. Any information about the user that is needed application wide can be stored in the session data. However, you want the session data to be lightweight, so please do not put large arrays of data in the session.
Due to the amount of time some of the analytics takes to process progress bars are an essential. There is no way to send multiple messages through https requests in a non cumbersome or verbose way. This is where socket.IO shines. Each client has its own socketId that is generated when they log in. That socketId is one's gateway to sending information to the user. Currently, there is one channel setup for communication between the user and the server and that channel is "progress". If more information needs to be shared between the user and the server one could generate a new channel to send information through. The SocketManager is responsible for all socket based communications which is located in socketManager.js.