Python从入门到实战配套程序代码,书籍更正,代码更正,项目拓展。购买后请下方加我微信,邀请你到读者售后群,方便交流。由于部分同学访问github很慢甚至打不开,可以使用我的代码镜像仓库:https://www.github.cafe
京东购买如下: https://item.jd.com/14049708.html

希望本书的内容能够教会你学习爬虫的方法,而不是复制粘贴代码。书籍中难免有表述错误的地方,如果有疑问,你可以与我联系。
如果本仓库的代码过时等问题,你可以在此提Issues,也可以与联系出版社反馈,我将尽快的回答你,并且更新修复后的代码在本仓库。
读者可以直接邮箱对我提问,详细说明你遇到的问题,请反复检查确保是代码真实存在的问题再问,提问基本格式:详细问题描述+详细的截图
我的邮箱:[email protected] ,我的微信:hxgsrubxjogxeeag
见b站:https://space.bilibili.com/591228087
由于排版等原因,可能书中小部分内容写错了,在此更正,非常抱歉。
- P38页,最后一个段落中“因为链接样式的优先级高于内嵌样式”,这一句话错了。优先级依然是文首说到:内嵌式>导入式>链接式
99一个二维码,还售罄??

不存在,只需要不到一毛钱成本就可以制作完成。到知数云https://data.zhishuyun.com/services ,申请艺术二维码API,可免费体验20次:

参考代码如下,你只需要修改token为你自己的token即可:
# coding=gbk
'''
作者:川川
书籍: Python网络爬虫入门到实战
京东地址:https://item.jd.com/14049708.html
分析文章:https://blog.csdn.net/weixin_46211269/article/details/132537579
'''
import requests
url = "https://api.zhishuyun.com/qrart/generate?token=你自己的token"
headers = {
"accept": "application/json",
"content-type": "application/json"
}
payload = {
"type": "link",
"content": "https://chat.zhangsan.cloud/",
"prompt": "mexican tacos",
"pattern": "rd1",
"preset": "vibrant-palette",
"qrw": 2,
"rawurl": True,
"padding_level": "5",
"aspect_ratio": "768x768",
"position": "center",
"pixel_style": "square",
"marker_shape": "square",
"sub_marker": "square",
"rotate": "0",
"ecl": "M",
"padding_noise": "0.25"
}
response = requests.post(url, json=payload, headers=headers)
# 解析JSON响应
response_data = response.json()
image_url = response_data.get("image_url")
print(image_url)
if image_url:
# 获取图像数据
image_response = requests.get(image_url)
image_data = image_response.content
# 将图像数据保存为本地文件
image_filename = "AI.jpg" # 本地文件名
with open(image_filename, "wb") as image_file:
image_file.write(image_data)
print(f"图像已保存为 {image_filename}")
else:
print("未找到图像URL")注意:这里使用selenium最新版4.0+,否则小部分语法不支持。 分析文章:https://blog.csdn.net/weixin_46211269/article/details/132680063
# coding=gbk
'''
作者:川川
书籍: Python网络爬虫入门到实战
京东地址:https://item.jd.com/14049708.html
'''
import pandas as pd
import csv
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import time
from selenium.webdriver.chrome.service import Service # 新增
from selenium.webdriver.common.by import By
# start_time = time.time() # 计算程序运行时间
# 获取网页内容
def get_one_page(year):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
# https://www.shanghairanking.cn/rankings/bcur/%s11
url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))
# print(url)
response = requests.get(url, headers=headers)
if response.content is not None:
content = response.content.decode('utf-8')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
return content.encode('gbk', errors='ignore').decode('gbk')
else:
content = ""
return content.encode('gbk', errors='ignore').decode('gbk')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
except RequestException:
print('爬取失败')
def extract_university_info(data):
soup = BeautifulSoup(data, 'html.parser')
table = soup.find('table', {'data-v-4645600d': "", 'class': 'rk-table'})
tbody = table.find('tbody', {'data-v-4645600d': ""})
rows = tbody.find_all('tr')
university_info = []
for row in rows:
rank = row.find('div', {'class': 'ranking'}).text.strip()
univ_name_cn = row.find('a', {'class': 'name-cn'}).text.strip()
univ_name_en = row.find('a', {'class': 'name-en'}).text.strip()
location = row.find_all('td')[2].text.strip()
category = row.find_all('td')[3].text.strip()
score = row.find_all('td')[4].text.strip()
rating = row.find_all('td')[5].text.strip()
info = {
"排名": rank,
"名称": univ_name_cn,
"Name (EN)": univ_name_en,
"位置": location,
"类型": category,
"总分": score,
"评分": rating
}
university_info.append(info)
# 打印数据
print(
f"排名: {rank}, 名称: {univ_name_cn}, Name (EN): {univ_name_en}, 位置: {location}, 类型: {category}, 总分: {score}, 评分: {rating}"
)
return university_info
# data = get_one_page(2023)
# 获取一个页面内容
# print(extract_university_info(data))
def get_total_pages(pagination_html):
soup = BeautifulSoup(pagination_html, 'html.parser')
pages = soup.find_all('li', class_='ant-pagination-item')
if pages:
return int(pages[-1].text)
return 1
html = get_one_page(2023)
def get_data_from_page(data):
content = extract_university_info(data)
return content
total_pages = get_total_pages(html)
# print(total_pages)
def write_to_csv(data_list, filename='output.csv'):
# 检查文件是否存在,以决定是否写入表头
file_exists = False
try:
with open(filename, 'r', encoding='utf-8'):
file_exists = True
except FileNotFoundError:
pass
with open(filename, 'a', newline='', encoding='utf-8') as csvfile:
fieldnames = ["排名", "名称", "Name (EN)", "位置", "类型", "总分", "评分"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
if not file_exists:
writer.writeheader() # 写入表头
for data in data_list:
writer.writerow(data)
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
service = Service(executable_path='chromedriver.exe')
browser = webdriver.Chrome(service=service)
browser.get("https://www.shanghairanking.cn/rankings/bcur/202311")
for page in range(1, total_pages + 1):
jump_input_locator = browser.find_element(By.XPATH, '//div[@class="ant-pagination-options-quick-jumper"]/input')
jump_input = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable(jump_input_locator)
)
jump_input.clear()
jump_input.send_keys(page) # 输入页码
jump_input.send_keys(Keys.RETURN) # 模拟 Enter 键
time.sleep(3) # 等待页面加载
html = browser.page_source
content = get_data_from_page(html)
write_to_csv(content)
time.sleep(3)
browser.quit()# coding=gbk
分析文章:https://blog.csdn.net/weixin_46211269/article/details/132701932
'''
作者:川川
书籍: Python网络爬虫入门到实战
京东地址:https://item.jd.com/14049708.html
'''
from selenium import webdriver
import json
from selenium.webdriver.chrome.service import Service # 新增
import time
service = Service(executable_path='chromedriver.exe')
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")
print('请在十秒内扫码登录')
time.sleep(10)
dictCookies = browser.get_cookies()
jsonCookies = json.dumps(dictCookies)
with open('cookies.txt', 'w') as f:
f.write(jsonCookies)
print('cookies保存成功!')# coding=gbk
'''
作者:川川
书籍: Python网络爬虫入门到实战
京东地址:https://item.jd.com/14049708.html
'''
import json
from selenium import webdriver
import time
browser = webdriver.Chrome()
with open('cookies.txt', 'r', encoding='u8') as f:
cookies = json.load(f)
browser.get("https://www.csdn.net/")
for cookie in cookies:
browser.add_cookie(cookie)
browser.get("https://www.csdn.net/")
time.sleep(10)# coding=gbk
'''
作者:川川
书籍: Python网络爬虫入门到实战
京东地址:https://item.jd.com/14049708.html
'''
import requests
import re
import time
import os
# 请求函数
def request_get(url, ret_type="text", timeout=5, encoding="GBK"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
res = requests.get(url=url, headers=headers, timeout=timeout)
res.encoding = encoding
if ret_type == "text":
return res.text
elif ret_type == "image":
return res.content
# 字符串索引,获取重点源码部分
def split_str(text, s_html, e_html):
# text为完整源码,获取列表的源码
start = text.find(s_html) + len(e_html)
end = text.find(e_html)
# 索引读取
origin_text = text[start:end]
return origin_text
def format_detail(text):
# 传入一张的源码 获取链接
origin_text = split_str(text, '<div class="pic">', '<div class="pic-down">')
# 写正则表达式
pattern = re.compile('src="(.*?)"')
# 正在匹配
image_src = pattern.search(origin_text).group(1)
print('图片链接')
print(image_src)
# 保存图片
save_image(image_src)
# 解析函数,获取正确的下载地址
def format(text):
# 获取列表部分所有源码
origin_text = split_str(text, '<div class="list">', '<div class="page">')
# 写正则
pattern = re.compile('href="(.*?)"')
# 匹配出图片链接所有href,是个列表
hrefs = pattern.findall(origin_text)
# 筛选出那些包含子字符串 "desk" 的元素,否则不是图片链接
hrefs = [i for i in hrefs if i.find("desk") > 0]
# print('看看')
# print(hrefs)
for href in hrefs:
# 得到每一张图片链接
url = f"http://www.netbian.com{href}"
print(f"正在下载页面:{url}")
# 请求这一页的源码
text = request_get(url)
# 解析这一页的内容
format_detail(text)
return text
# 存储函数
def save_image(image_src):
# 文件夹名
folder_name = 'downloaded_images'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
content = request_get(image_src, "image")
# 用时间戳来给文件命名
file_name = f"{str(time.time())}.jpg"
# 创建路径
file_path = os.path.join(folder_name, file_name)
# 写入文件
with open(file_path, "wb") as f:
f.write(content)
print(f"图片保存成功: {file_path}")
# 主函数
def main():
urls = [f"http://www.netbian.com/mei/index_{i}.htm" for i in range(2, 201)]
for url in urls:
print('休息1s继续爬...')
time.sleep(1)
print("抓取列表页地址为:", url)
# 获取图片链接内容
text = request_get(url)
format(text)
if __name__ == '__main__':
main()
免费下载代理,筛选后以CSV格式导出:
https://geonode.com/free-proxy-list
留其中IP列即可,使用该CSV文件构建代理池,每次请求随意获取一个代理:
# coding=gbk
'''
https://geonode.com/free-proxy-list
'''
import csv
from random import choice
proxy_file_path = 'Proxy.csv'
proxy_list = []
with open(proxy_file_path, 'r') as csvfile:
csv_reader = csv.reader(csvfile)
next(csv_reader)
for row in csv_reader:
if row:
proxy_list.append(row[0])
random_proxy = choice(proxy_list)
print(random_proxy)
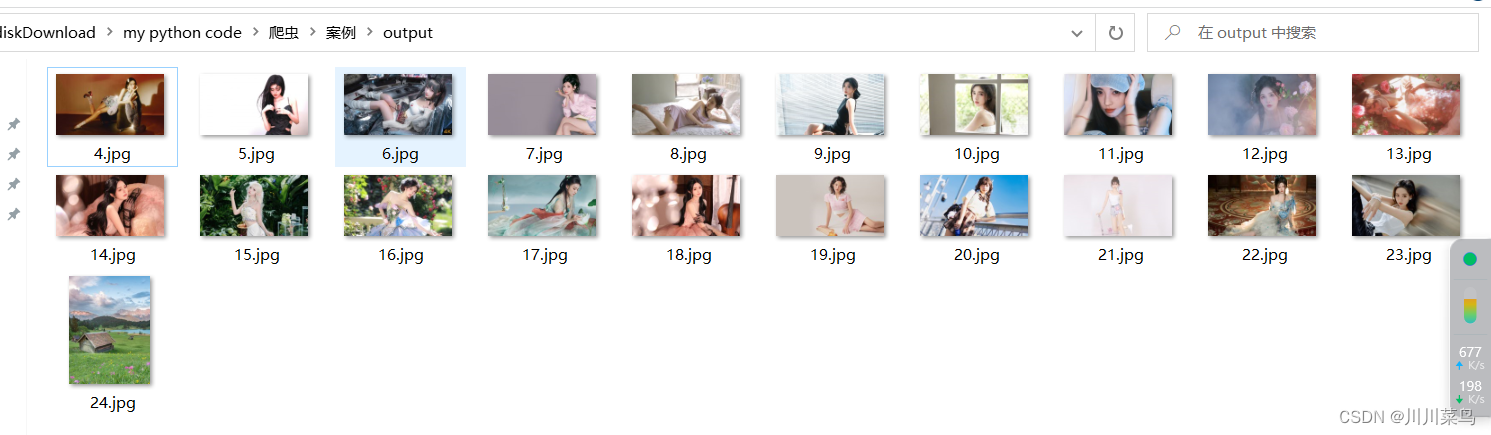
原理:抓取该链接中所有的图片格式。基于selenium来获取,自动下载到output文件夹中。
from selenium import webdriver
import requests as rq
import os
from bs4 import BeautifulSoup
import time
# Enter Path : chromedriver.exe
# Enter URL : http://www.netbian.com/meinv/index_2.htm
path = input("Enter Path : ")
url = input("Enter URL : ")
output = "output"
def get_url(path, url):
driver = webdriver.Chrome(executable_path=r"{}".format(path))
driver.get(url)
print("loading.....")
res = driver.execute_script("return document.documentElement.outerHTML")
return res
def get_img_links(res):
soup = BeautifulSoup(res, "lxml")
imglinks = soup.find_all("img", src=True)
return imglinks
def download_img(img_link, index):
try:
extensions = [".jpeg", ".jpg", ".png", ".gif"]
extension = ".jpg"
for exe in extensions:
if img_link.find(exe) > 0:
extension = exe
break
img_data = rq.get(img_link).content
with open(output + "\\" + str(index + 1) + extension, "wb+") as f:
f.write(img_data)
f.close()
except Exception:
pass
result = get_url(path, url)
time.sleep(60)
img_links = get_img_links(result)
if not os.path.isdir(output):
os.mkdir(output)
for index, img_link in enumerate(img_links):
img_link = img_link["src"]
print("Downloading...")
if img_link:
download_img(img_link, index)
print("Download Complete!!")如下所示:
import requests
import openpyxl
import time
# 定义全局请求头
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36'}
# 获取数据抓包,返回json数据集
def getData(url, params):
response = requests.get(url, params=params, headers=HEADERS)
return response.json()
# 获取文章数
def getArticleCount(username):
url = 'https://blog.csdn.net/community/home-api/v1/get-tab-total'
params = {'username': username}
response = requests.get(url, params=params, headers=HEADERS)
return response.json()['data']['blog']
# 保存json对象数据到excel中
def saveData(url, username, save_path):
wb = openpyxl.Workbook()
ws = wb.active
ws.title = 'CSDN用户文章信息'
params = {'page': '1', 'size': '20', 'businessType': 'blog', 'noMore': 'false', 'username': username}
total_blogs = getArticleCount(username)
print('用户%s的博客数:%d' % (username, total_blogs))
for i in range(int(total_blogs / 20) + 1):
params['page'] = str(i + 1)
json_data = getData(url, params=params)
if i == 0:
ws.append(list(json_data['data']['list'][0].keys()))
for index, article in enumerate(json_data['data']['list'], start=i * 20 + 1):
values = [str(value) for value in article.values()]
ws.append(values)
print('正在爬取第%d篇文章' % index)
if index >= total_blogs:
break
wb.save(save_path)
print('爬取成功!!!')
# 读取文件访问所有文章
def read_excel(excelUrl, username):
wb = openpyxl.load_workbook(excelUrl)
ws = wb.active
rows = getArticleCount(username)
for row in ws.iter_rows(min_row=2, max_row=rows + 1, min_col=4, max_col=4):
for cell in row:
try:
requests.get(cell.value)
print('访问', cell.value, '成功', end='\t\t')
except requests.RequestException as e:
print('访问', cell.value, '失败', end='\t\t')
print()
if __name__ == '__main__':
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
# 强调:请在这里替换为你自己的用户名,就是主页的后缀
username = 'weixin_46211269'
save_path = './CSDN用户文章信息.xlsx'
saveData(url, username, save_path)
read_excel(save_path, username)
结果如下:
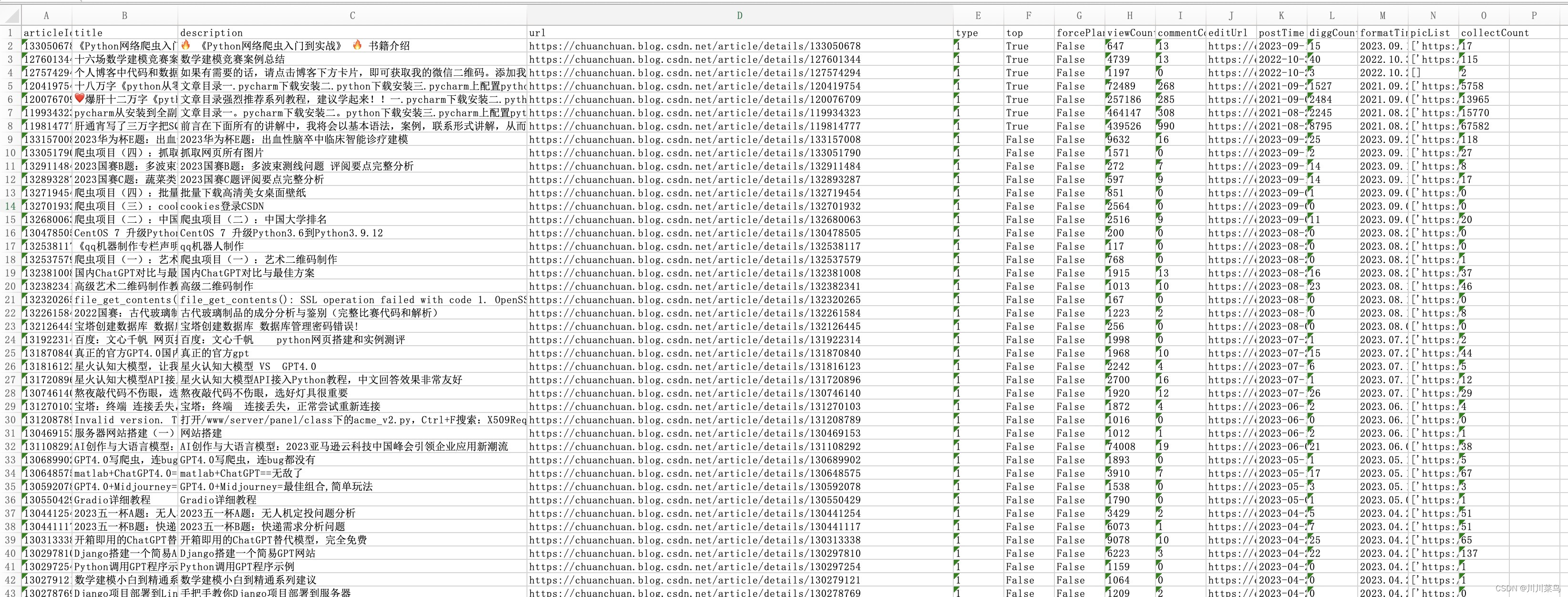
分析文章:https://chuanchuan.blog.csdn.net/article/details/133129610
完整代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import csv
import json
import urllib.request
# 获取动态IP
def get_dynamic_ip():
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl_5dede465-zone-try-country-us:[email protected]:22225',
'https': 'http://brd-customer-hl_5dede465-zone-try-country-us:[email protected]:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
response_str = response.decode('utf-8')
ip = json.loads(response_str)['ip']
return ip
# 使用动态IP配置WebDriver
def configure_driver_with_proxy(ip):
PROXY = ip
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--proxy-server={PROXY}')
# 初始化浏览器
driver = webdriver.Chrome()
return driver
# 主逻辑
ip = get_dynamic_ip()
print(f"Using IP: {ip}")
driver = configure_driver_with_proxy(ip)
# 打开亚马逊网站
driver.get("https://www.amazon.cn/")
time.sleep(3)
# 在搜索框中输入“iPhone 15”
search_box = driver.find_element(By.ID, "twotabsearchtextbox")
search_box.send_keys("iPhone 15")
search_box.send_keys(Keys.RETURN)
# 等待页面加载
time.sleep(3)
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
# 创建CSV文件并写入数据
with open('amazon_products_multiple_pages.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Title', 'Price', 'Image URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 循环遍历多个页面,使用代理的ip去爬多页
for page in range(1, 9):
time.sleep(2)
print(f"Scraping page {page}..")
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
for index, product in enumerate(product_elements):
try:
title = product.find_element(By.CSS_SELECTOR, ".a-text-normal").text
price = product.find_element(By.CSS_SELECTOR, ".a-price-whole").text
image_url = product.find_element(By.CSS_SELECTOR, "img.s-image").get_attribute("src")
# print(f"Product {index + 1}:")
# print(f"Title: {title}")
# print(f"Price: {price} RMB")
# print(f"Image URL: {image_url}")
# 写入CSV文件
writer.writerow({'Title': title, 'Price': price, 'Image URL': image_url})
except Exception as e:
print(f"Skipping product {index + 1} due to missing information.")
# 点击“下一页”按钮
try:
next_button = driver.find_element(By.CSS_SELECTOR, ".s-pagination-next")
next_button.click()
time.sleep(3) # 等待下一页加载
except Exception as e:
print("No more pages to scrape.")
break
time.sleep(10)
# 关闭浏览器
driver.quit()
如果打开遇到验证码,以下是解决的方案:
# 使用XPath定位图片并获取其src属性
image_element = driver.find_element(By.XPATH, "/html/body/div/div[1]/div[3]/div/div/form/div[1]/div/div/div[1]/img")
image_url = image_element.get_attribute('src')
# 使用requests下载图片
response = requests.get(image_url, stream=True)
response.raise_for_status()
# 保存图片到磁盘
with open('c.png', 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
ocr = ddddocr.DdddOcr()
with open('c.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="captchacharacters"]').send_keys(res)
driver.find_element(By.XPATH, '/html/body/div/div[1]/div[3]/div/div/form/div[2]/div/span/span/button').click()
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import requests
import re
# 设置保存路径
path = './girl'
# 目标url
url = "http://pic.netbian.com/4kmeinv/index.html"
# 伪装请求头 防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
# 正则匹配提取想要的数据 得到图片链接和名称
img_info = re.findall('img src="(.*?)" alt="(.*?)" /', response.text)
for src, name in img_info:
img_url = 'http://pic.netbian.com' + src # 加上 'http://pic.netbian.com'才是真正的图片url
img_content = requests.get(img_url, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
print(f"正在为您下载图片:{img_name}")
f.write(img_content)
视频讲解:https://www.bilibili.com/video/BV1xu4y177BC/?spm_id_from=333.999.0.0 文章:https://chuanchuan.blog.csdn.net/article/details/134194689
selenium实现:
from flask import Flask, render_template, request
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from datetime import datetime
from queue import Queue, Empty
app = Flask(__name__)
# 创建一个队列保存浏览器实例
browser_queue = Queue(maxsize=2) # 这里的maxsize可以根据你的需求调整
def get_browser():
try:
browser = browser_queue.get_nowait()
except Empty:
if browser_queue.full():
old_browser = browser_queue.get()
old_browser.quit()
chrome_options = Options()
chrome_options.add_argument("--headless")
browser = webdriver.Chrome(options=chrome_options)
return browser
def return_browser(browser):
# 将浏览器实例放回队列中
browser_queue.put(browser)
@app.route('/', methods=['GET', 'POST'])
def index():
start_time = datetime.now()
result = None
time_elapsed = 0
if request.method == 'POST':
user_input = request.form.get('user_input')
if len(user_input) > 300:
return render_template('index.html', result="输入的文本超过了 300 个字符。", timeElapsed=time_elapsed)
browser = get_browser() # 从队列中获取浏览器实例
try:
browser.get('https://writer.com/ai-content-detector/')
input_element = browser.find_element(By.XPATH, '/html/body/div[3]/div[2]/div[2]/div[1]/form/div[2]/textarea')
input_element.send_keys(user_input)
detect_button = browser.find_element(By.XPATH, '/html/body/div[3]/div[2]/div[2]/div[1]/form/button')
browser.execute_script("arguments[0].click();", detect_button)
WebDriverWait(browser, 10).until(
EC.visibility_of_element_located((By.ID, 'ai-percentage'))
)
percentage_element = browser.find_element(By.ID, 'ai-percentage')
result = f'AI生成百分比为: {percentage_element.text}%'
finally:
return_browser(browser) # 将浏览器实例放回队列中
end_time = datetime.now()
time_elapsed = (end_time - start_time).seconds
return render_template('index.html', result=result, timeElapsed=time_elapsed)
if __name__ == '__main__':
app.run(debug=False)抓取接口进行实现,速度更快:
from flask import Flask, render_template, request
import requests
from datetime import datetime
app = Flask(__name__)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
'Origin': 'https://writer.com',
'Referer': 'https://writer.com/ai-content-detector/',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'text/plain, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Sec-Ch-Ua': '"Chromium";v="118", "Google Chrome";v="118", "Not=A?Brand";v="99"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': 'Windows',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'Cookie': 'mutiny.user.token=c64da415-54d0-4c6d-9795-122c6acc2ce2; _gcl_au=1.1.1398885097.1698945402; traffic_src={"ga_gclid":"","ga_source":"google","ga_medium":"organic","ga_campaign":"","ga_content":"","ga_keyword":"(not provided)","ga_landing_page":"https://writer.com/ai-content-detector/"}; _rdt_uuid=1698945402575.25da91b6-60f8-4a95-8224-b8a6b14cdbda; cb_user_id=null; cb_group_id=null; cb_anonymous_id=%2284aafc75-f11b-4644-8d6e-08bd275fd45a%22; _clck=2alrmh|2|fgd|0|1401; hubspotutk=ed3255630247916c775fae866532a97b; __hssrc=1; OptanonAlertBoxClosed=2023-11-02T17:18:18.959Z; ajs_user_id=null; ajs_group_id=null; ajs_anonymous_id=%229d688975-a06f-49e3-ac6c-c6525bfcbe77%22; _gid=GA1.2.788250116.1698945706; _ga_PTDL30YN61=GS1.2.1698945710.1.1.1698945716.54.0.0; _ga=GA1.1.439872204.1698945402; mutiny.user.session=2a4f8206-e4e8-40d6-a707-e30b55b7d96a; mutiny.user.session_number=1; __hstc=117297753.ed3255630247916c775fae866532a97b.1698945405358.1698952211562.1698954156966.4; wordpress_test_cookie=WP%20Cookie%20check; jetpack_sso_original_request=http%3A%2F%2Fwriter.com%2Fwp-login.php%3Fredirect_to%3Dhttps%253A%252F%252Fwriter.com%252Fwp-admin%252F%26reauth%3D1; jetpack_sso_redirect_to=https%3A%2F%2Fwriter.com%2Fwp-admin%2F; jetpack_sso_nonce=m6lxyej0gmnexusohi7w; tk_ai=fyx5WYo7VrrlSEGRPGoPSKer; _uetsid=97cd66e079a311eebddb6dbe9738e37e; _uetvid=adc4fce0e28811eda5d8dff742ed6907; OptanonConsent=isIABGlobal=false&datestamp=Fri+Nov+03+2023+03%3A55%3A15+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=6.26.0&landingPath=NotLandingPage&groups=1%3A1%2C0_175949%3A1%2C0_175955%3A1%2C2%3A1%2C0_175947%3A1%2C3%3A1%2C0_175950%3A1%2C4%3A1%2C0_175962%3A1%2C0_175967%3A1%2C0_175960%3A1%2C0_180698%3A1%2C0_175959%3A1%2C0_180699%3A1%2C0_180707%3A1%2C0_180701%3A1%2C0_182460%3A1%2C0_175963%3A1%2C0_180703%3A1%2C0_180693%3A1%2C0_180697%3A1%2C0_180695%3A1%2C0_180700%3A1%2C0_175964%3A1%2C0_180702%3A1%2C0_180694%3A1%2C0_180706%3A1%2C8%3A1&consentId=f460ce62-468d-4204-927a-e69e4741f2d6&AwaitingReconsent=false; __hssc=117297753.3.1698954156966; _clsk=bafar6|1698954921053|3|1|w.clarity.ms/collect; _ga_JW9S1XHSVS=GS1.1.1698952208.2.1.1698954940.34.0.0' # 通常,Cookie 也是很重要的,但由于它包含了许多个人信息和会话信息,所以在这里我暂时注释掉了。如果需要,您可以加上。
}
@app.route('/', methods=['GET', 'POST'])
def index():
start_time = datetime.now()
result = None
time_elapsed = 0
if request.method == 'POST':
user_input = request.form.get('user_input')
if len(user_input) > 300:
return render_template('index.html', result="输入的文本超过了 300 个字符。", timeElapsed=time_elapsed)
# 构建POST数据
data = {
'action': 'ai_content_detector_recaptcha',
'inputs': user_input,
'token': '' # 根据您的信息,token为空
}
response = requests.post('https://writer.com/wp-admin/admin-ajax.php', data=data, headers=HEADERS)
response_data = response.json()
# 根据响应计算AI生成百分比
if response_data:
ai_percentage = response_data[0]['score'] * 100
result = f'AI生成百分比为: {ai_percentage:.2f}%'
end_time = datetime.now()
time_elapsed = (end_time - start_time).seconds
return render_template('index.html', result=result, timeElapsed=time_elapsed)
if __name__ == '__main__':
app.run(debug=False)index.html如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" rel="stylesheet">
<title>AI Content Detector</title>
</head>
<body class="bg-light">
<div class="container mt-5">
<div class="row">
<div class="col-md-8 offset-md-2">
<div class="card">
<div class="card-body">
<h4 class="card-title mb-4 text-center">AI 内容检测器</h4>
<form action="/" method="post">
<div class="form-group">
<textarea name="user_input" class="form-control" rows="6" placeholder="输入文本..." onkeyup="updateCount(this)">{{ request.form.get('user_input') }}</textarea>
<p id="length-warning" class="text-danger mt-2" style="display: none;">文本超过 300 个字符!</p>
<p id="char-count" class="text-muted mt-2">0/300</p>
</div>
<div class="text-center">
<input type="submit" class="btn btn-primary" value="检测">
<input type="button" class="btn btn-secondary ml-2" value="清空" onclick="clearText()">
<p class="text-muted mt-2">大致需要等待时间为20s</p>
检测时间消耗:<span id="timer">0</span> 秒
</div>
</form>
{% if result %}
<div class="mt-4">
<p class="text-success">{{ result }}</p>
<p class="text-muted">检测消耗时间大约为: <span id="final-timer">{{ timeElapsed }}</span> 秒</p>
</div>
{% endif %}
</div>
</div>
</div>
</div>
</div>
<script src="https://code.jquery.com/jquery-3.5.1.slim.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@popperjs/[email protected]/dist/umd/popper.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.5.2/js/bootstrap.min.js"></script>
<script>
function updateCount(textarea) {
const maxLength = 300;
const warning = document.getElementById('length-warning');
const charCount = document.getElementById('char-count');
const submitButton = document.querySelector('input[type="submit"]');
const currentLength = textarea.value.length;
charCount.textContent = `${currentLength}/${maxLength}`;
if (currentLength > maxLength) {
warning.style.display = 'block';
submitButton.disabled = true;
} else {
warning.style.display = 'none';
submitButton.disabled = false;
}
}
function clearText() {
document.querySelector('textarea').value = '';
document.getElementById('char-count').textContent = '0/300';
timeElapsed = 0;
document.getElementById('timer').textContent = timeElapsed;
}
let timerInterval;
let timeElapsed = 0;
function startTimer() {
if (timerInterval) {
clearInterval(timerInterval);
}
// Reset time only when starting a new detection
timeElapsed = 0;
document.getElementById('timer').textContent = timeElapsed;
timerInterval = setInterval(function() {
timeElapsed++;
document.getElementById('timer').textContent = timeElapsed;
}, 1000);
}
document.querySelector('input[type="submit"]').addEventListener('click', startTimer);
</script>
</body>
</html>