PyTorch单机多核训练方案有两种:
-
nn.DataParallel,实现简单,不涉及多进程; -
torch.nn.parallel.DistributedDataParallel,torch.utils.data.distributed.DistributedSampler结合多进程实现。
第二种方式效率更高,同时支持多节点分布式实现。
CNN模型训练MNIST手写数据集,相关代码:
- model.py:定义一个简单的CNN网络
- data.py:MNIST训练集和数据集准备
- single_gpu_train.py:单GPU训练代码
torch.distributed.launch命令介绍
usage: launch.py [-h] [--nnodes NNODES] [--node_rank NODE_RANK]
[--nproc_per_node NPROC_PER_NODE] [--master_addr MASTER_ADDR] [--master_port MASTER_PORT]
[--use_env] [-m] [--no_python] [--logdir LOGDIR]
training_script ...
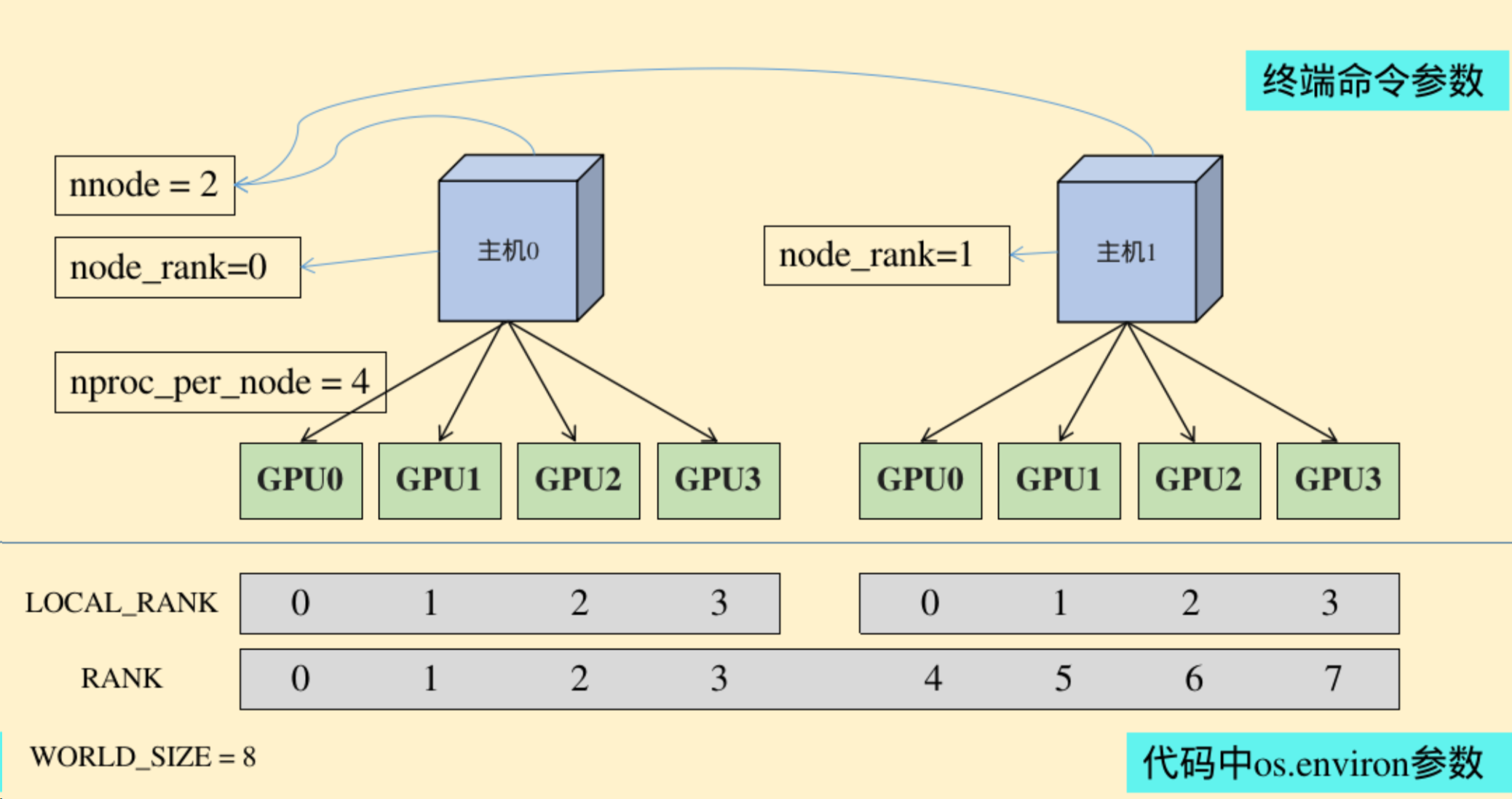
nnodes:节点的数量,通常一个节点对应一个主机 node_rank:节点的序号,从0开始 nproc_per_node:一个节点中显卡的数量 master_addr:master节点的ip地址,也就是0号主机的IP地址,该参数是为了让 其他节点 知道0号节点的位,来将自己训练的参数传送过去处理 master_port:master节点的port号,在不同的节点上master_addr和master_port的设置是一样的,用来进行通信
- WORLD_SIZE:os.environ[“WORLD_SIZE”]所有进程的数量
- LOCAL_RANK:os.environ[“LOCAL_RANK”]每张显卡在自己主机中的序号,从0开始
- RANK:os.environ[“RANK”]进程的序号,一般是1个gpu对应一个进程
model = nn.DataParallel(model)假设模型输入为(32, input_dim),这里的 32 表示batch_size,模型输出为(32, output_dim),使用 4 个GPU训练。
nn.DataParallel起到的作用是将这 32 个样本拆成 4 份,发送给 4 个GPU 分别做 forward,然后生成 4 个大小为(8, output_dim)的输出,然后再将这 4 个输出都收集到cuda:0上并合并成(32, output_dim)。
此外,loss部分还需要取平均值:
loss = loss.mean() # 将多个GPU返回的loss取平均分布式数据并行(distributed data parallel),多进程实现
-
启动多个进程(进程数等于GPU数),每个进程独享一个GPU,每个进程都会独立地执行代码。
-
每个进程都会初始化一份训练数据集,使用数据集中的不同记录做训练,即数据并行。通过
torch.utils.data.distributed.DistributedSampler函数实现数据并行 -
进程通过
local_rank变量来标识自己,local_rank为0的为master,其他是slave。这个变量是torch.distributed包帮我们创建的,使用方法如下:import argparse # 必须引入 argparse 包 parser = argparse.ArgumentParser() parser.add_argument("--local_rank", type=int, default=-1) args = parser.parse_args()
需要注意的是,新版本的pytorch需要主动get_rank,然后设置device :
torch.distributed.init_process_group(backend='nccl') args.local_rank = torch.distributed.get_rank() torch.cuda.set_device(args.local_rank) device = torch.device('cuda', args.local_rank)运行(此处
torch.distributed.launch不再适用):python -m torch.distributed.run --nproc_per_node=4 --nnodes=1 ddp.py
torch.distributed.launch以命令行参数的方式将args.local_rank变量注入到每个进程中,每个进程得到的变量值都不相同。比如使用 4 个GPU的话,则 4 个进程获得的
args.local_rank值分别为0、1、2、3。nproc_per_node表示每个节点需要创建多少个进程(使用几个GPU就创建几个);nnodes表示使用几个节点,因为我们是做单机多核训练,所以设为1。 -
因为每个进程都会初始化一份模型,为保证模型初始化过程中生成的随机权重相同,需要设置随机种子。方法如下:
def set_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)
详细代码参考:ddp_train.py
单机多卡到多机多卡主要的区别就是设置地址和端口
在0号机器上调用:
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 0 --master_addr='172.18.39.122' --master_port='29500' ddp.py
在1号机器上调用
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 1 --master_addr='172.18.39.122' --master_port='29500' ddp.py
- 命令中的【–master_addr=‘172.18.39.122’】指的是0号机器的IP,在0号机器上运行的命令中【node_rank】必须为0
- 只有当【nnodes】个机器全部运行,代码才会进行分布式的训练操作,否则一直处于等待状态