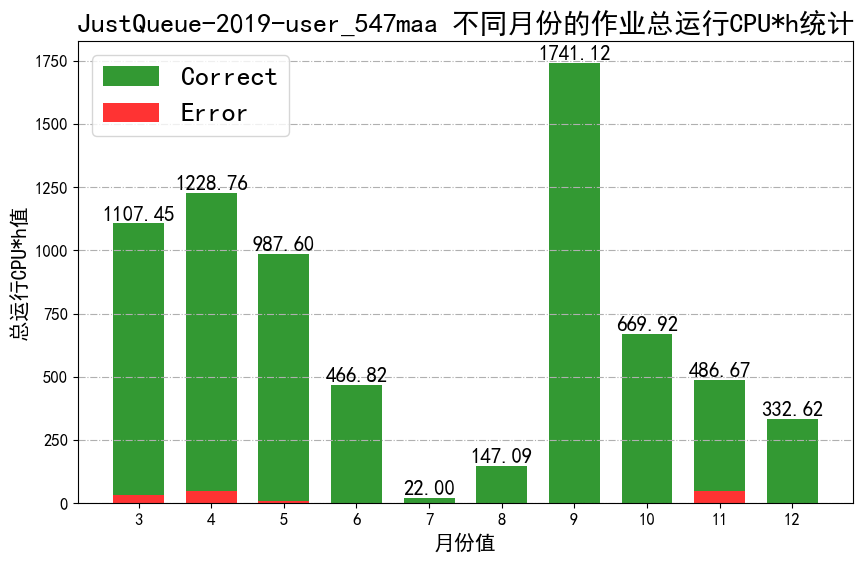
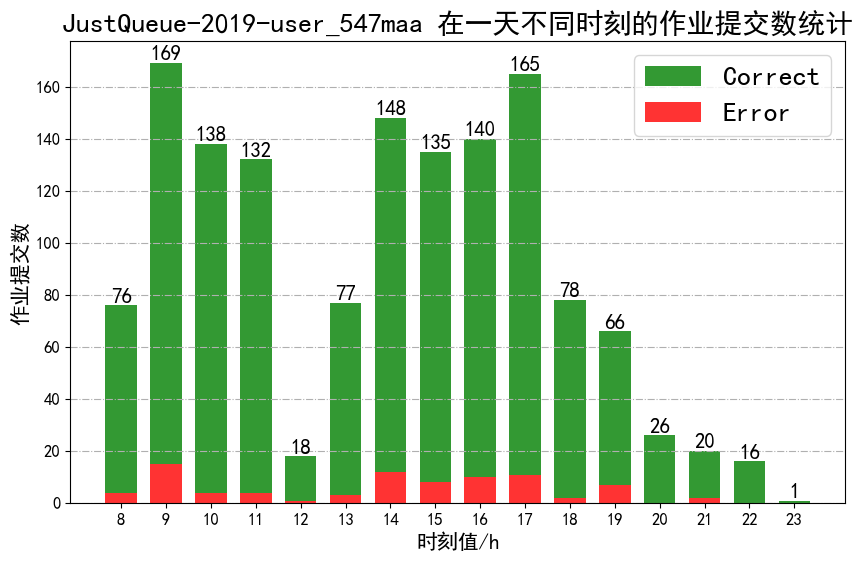
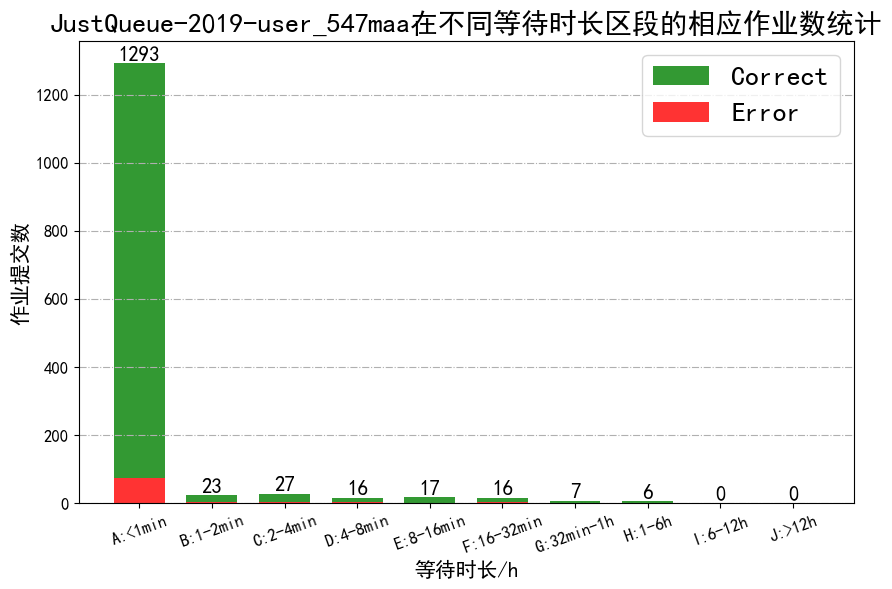
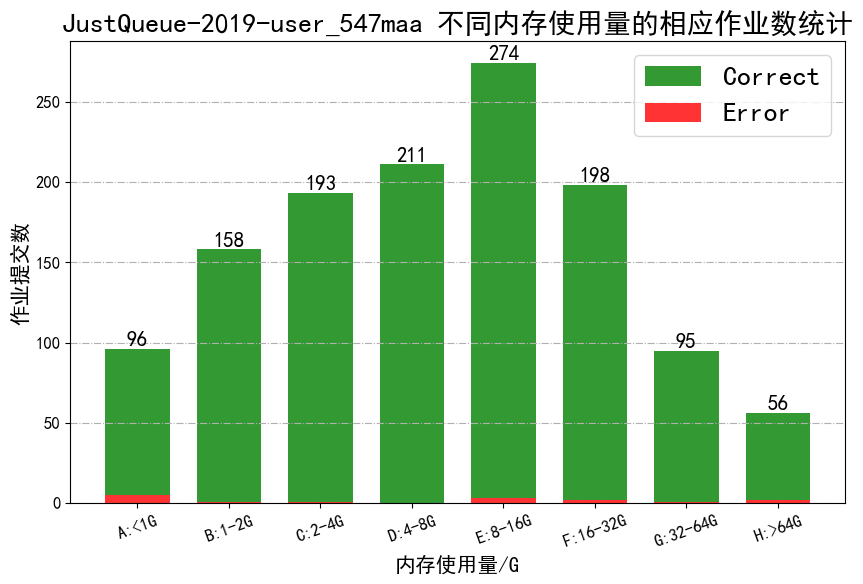
- Collect the bhist logs(Use python or shell script)
-
Parse the bhist log for each user
-
Modify each user's logfile to a proper excel format
- Visulize excel data tables, analyze user's submission habits and properties
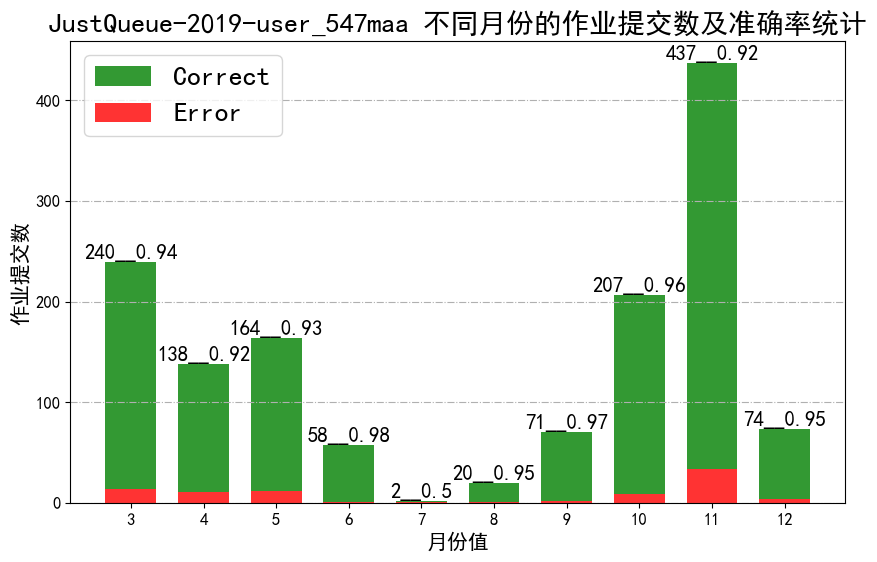
- job_accuracy
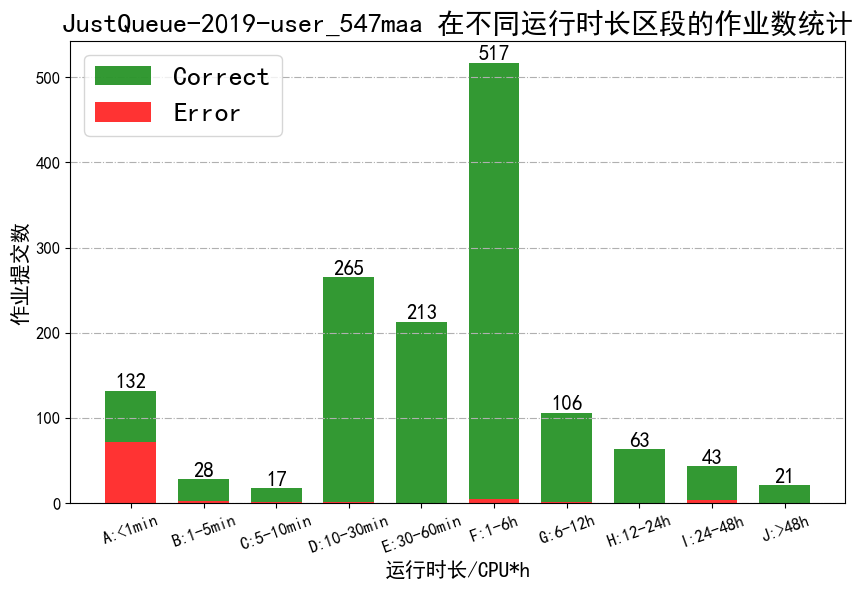
- job_runtime
- job_total_CPU_time
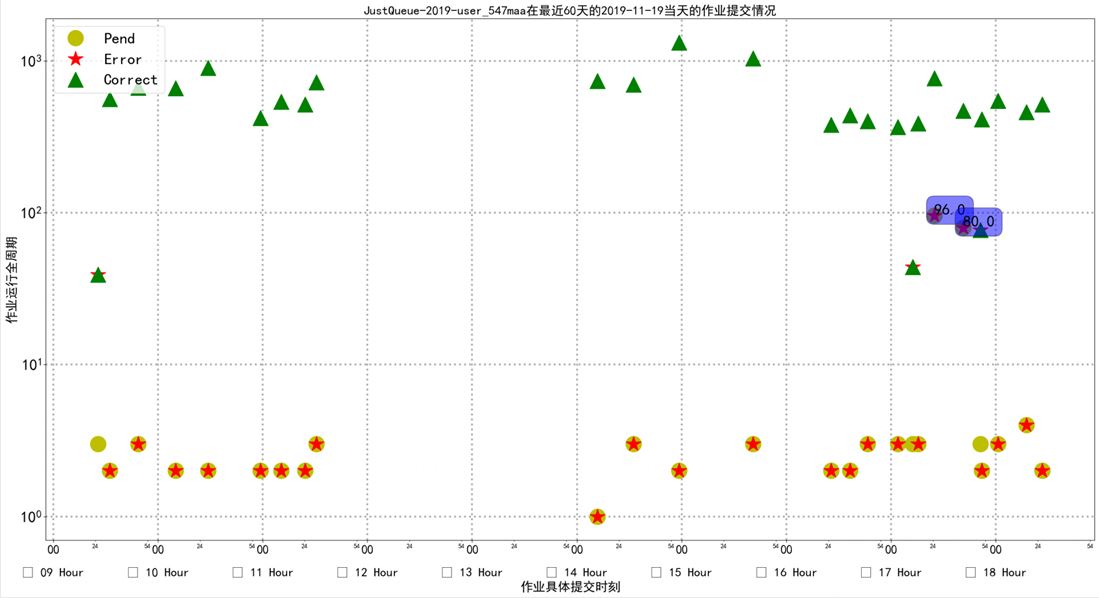
- job_submit_moment
- job_pend_time
- job_memory_used
- job_full_states_by_day
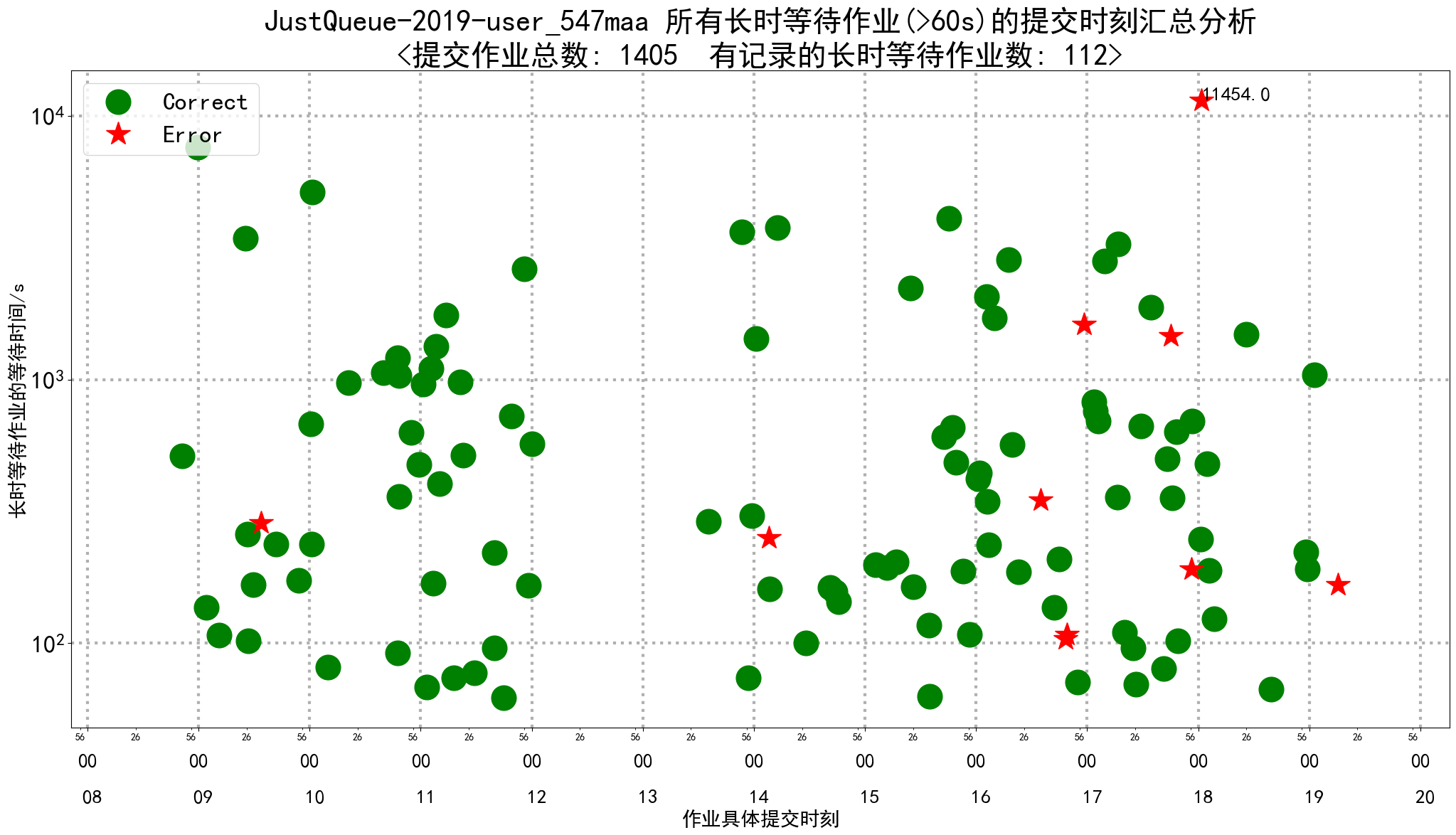
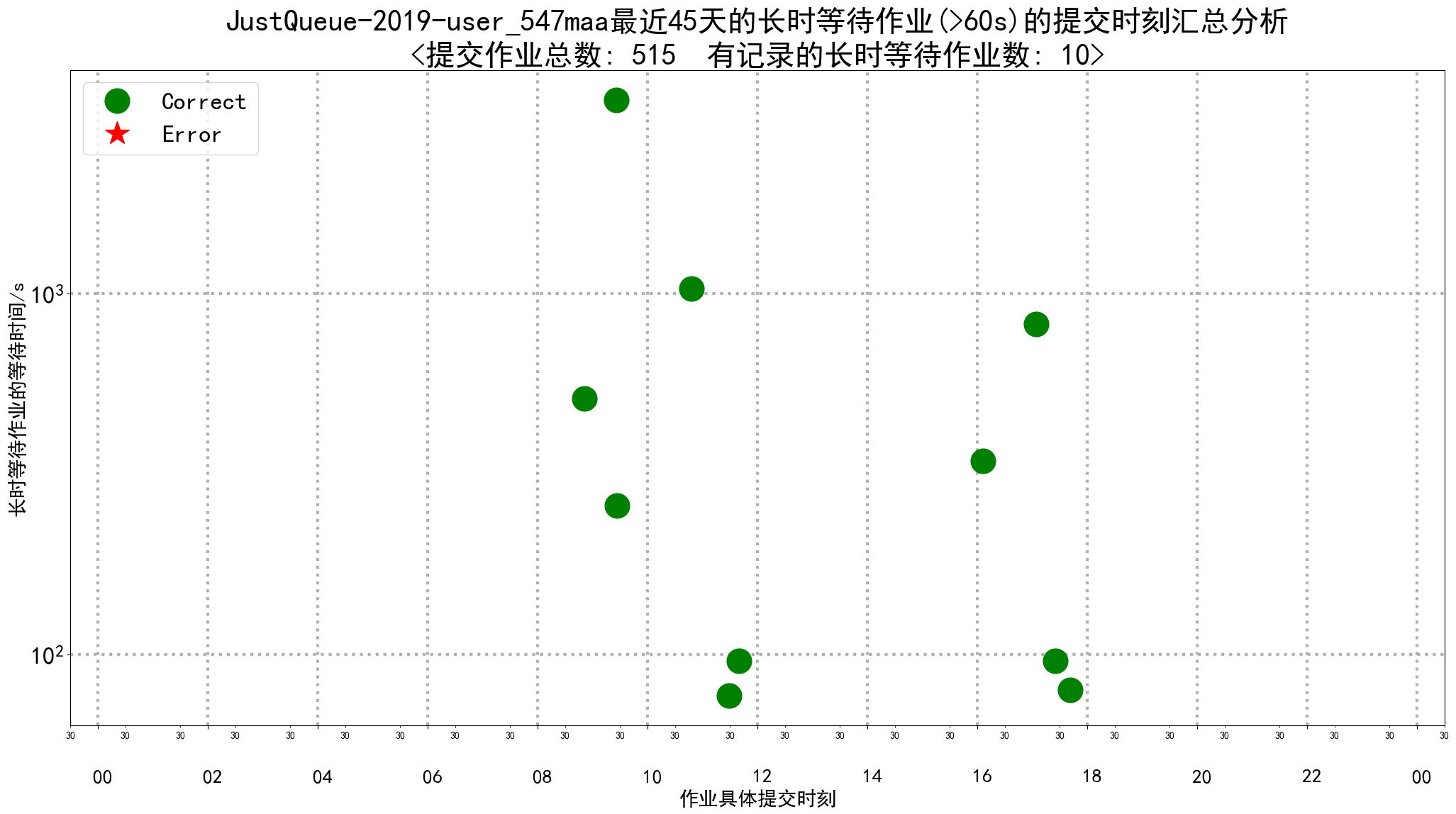
- job_long_pending_by_day
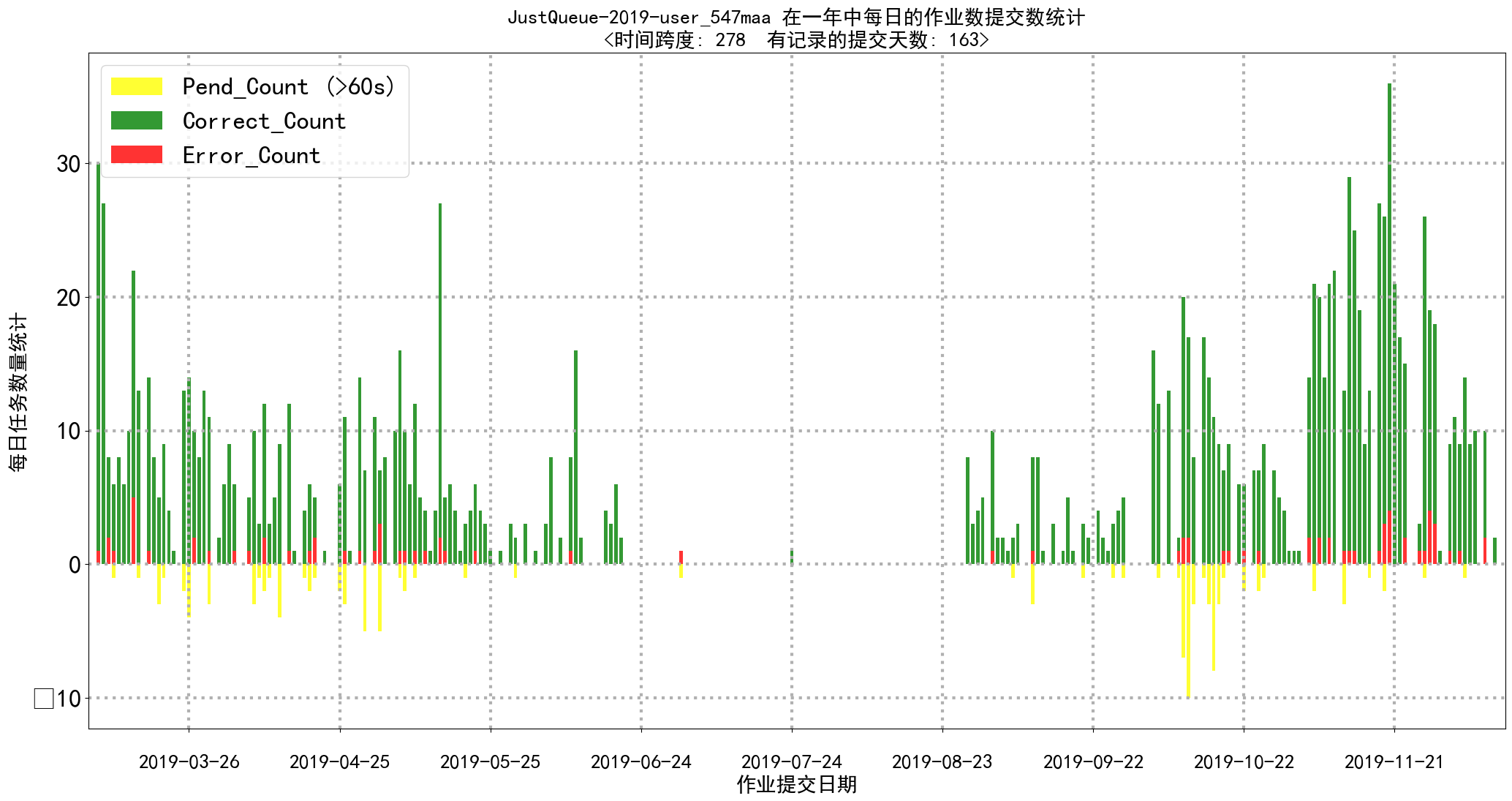
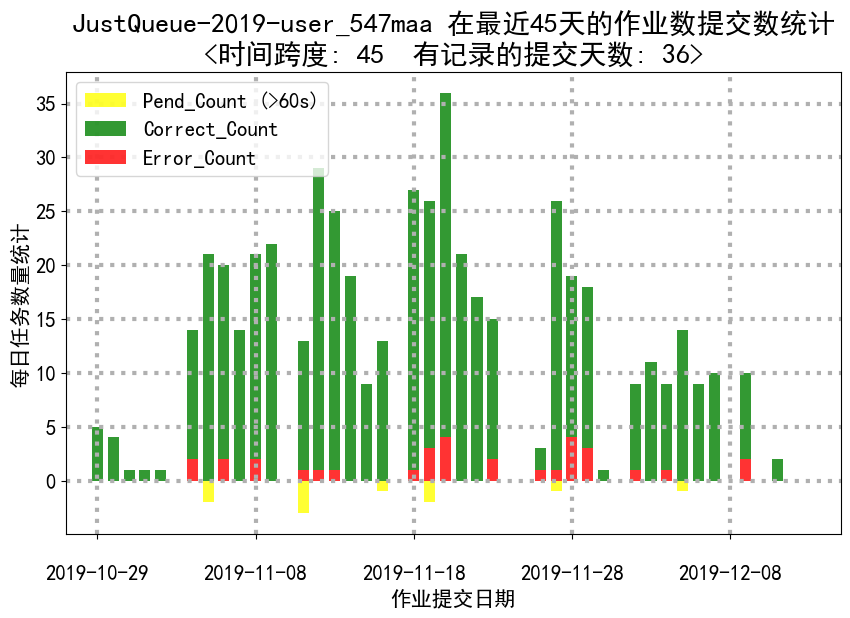
- job_submission_counts_by_day
- job_latest_features
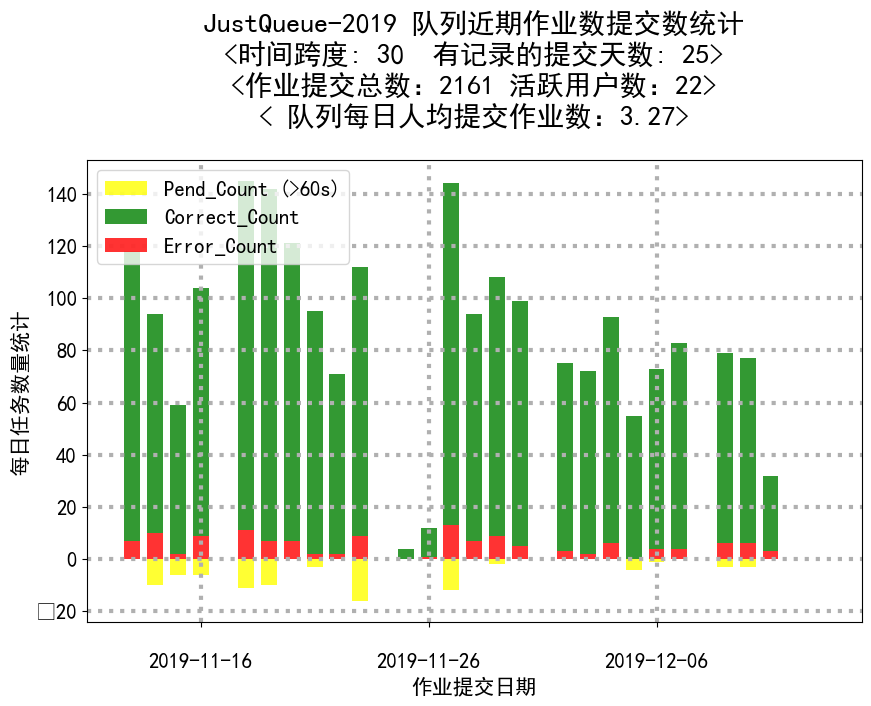
- Extract queue's features, analyze the queue's recent status
- User
- Status
- DateRange
- Days_Recorded
- Jobs_Recorded
- Accuracy
- MEAN_Memory
- MEAN_CPU_Time
- MEAN_Real_Time
- MEAN_Pend
- MEAN_Submission_Count_Recorded
- MEAN_Submission_Count
- latest_job_submission_counts
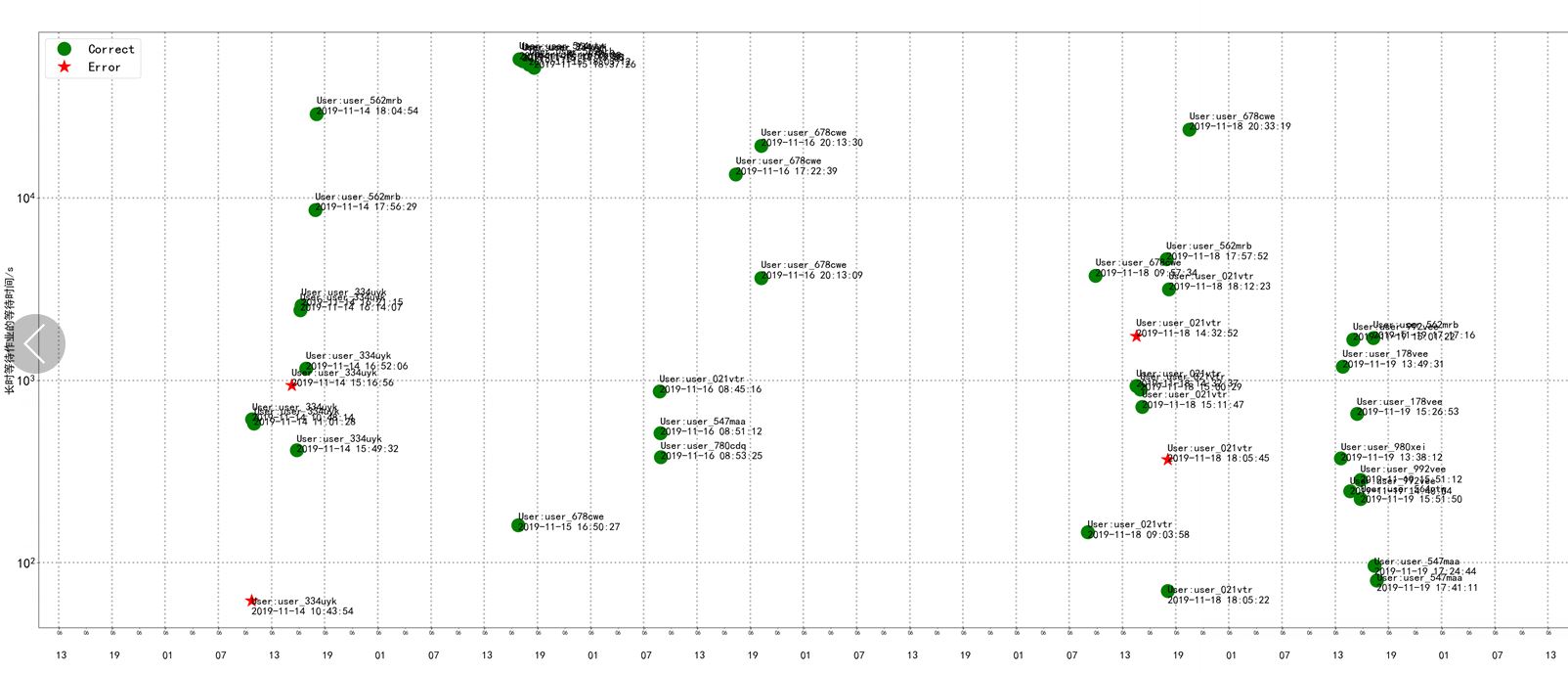
- latest_long_pending_jobs
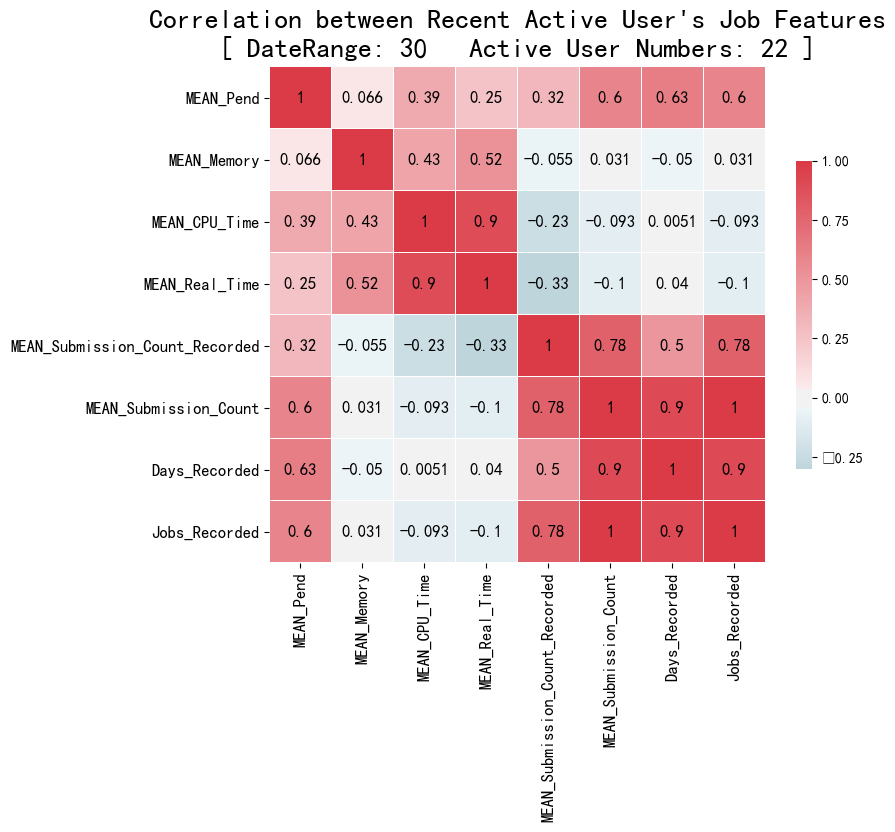
- Correlation analysis
- Further exploration, to be continued...
- user feature's cluster analysis
- bjobs logfile analysis
- Real-time sorting of long-pending jobs
- Perhaps use ELK tools
- 难点在于业务梳理,以及指标制定,工具使用还属其次
- 完成日志数据分析全流程:数据提取—数据清洗—特征定义—数据可视化—指导决策
- 代码规范、优化什么的没考虑