A pre-compiled Soccer-Twos environment with multi-agent Gym-compatible wrappers and a human-friendly visualizer. Built on top of Unity ML Agents to be used as final assignment for the Reinforcement Learning Minicourse at CEIA / Deep Learning Brazil.
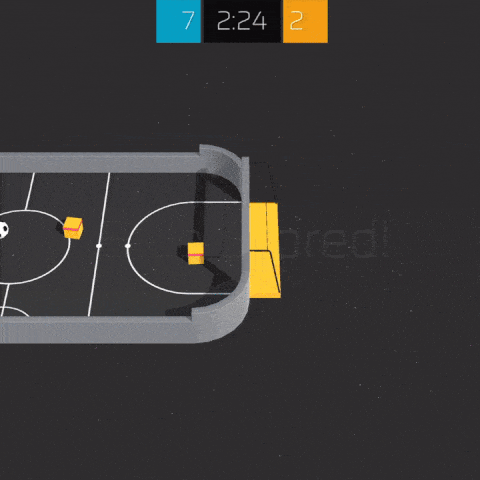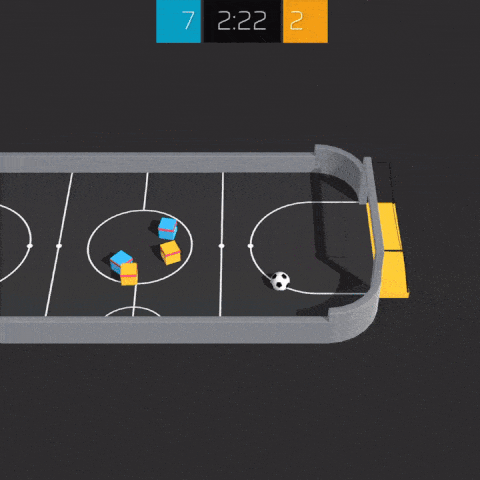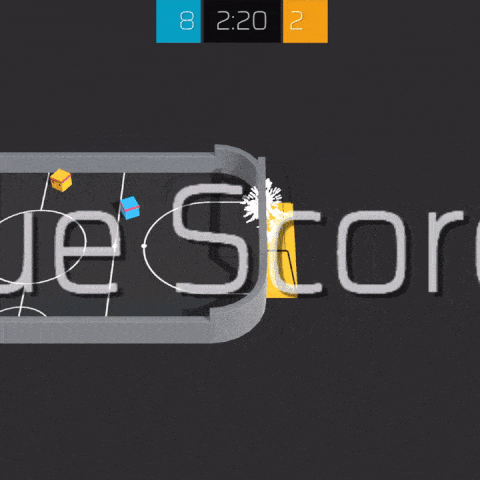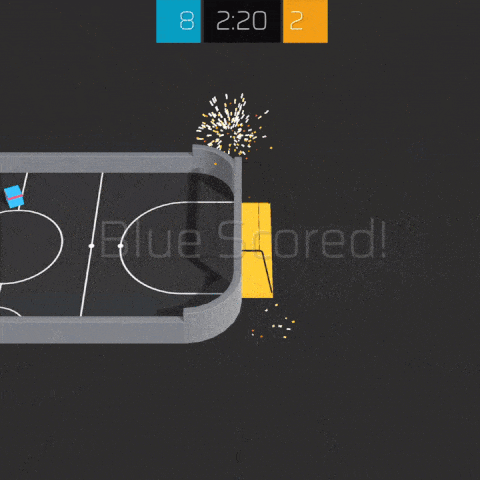
Pre-compiled versions of this environment are available for Linux, Windows and MacOS (x86, 64 bits). The source code for this environment is available here. Example agent training procedures are available here.
See requirements.txt.
Import this package and instantiate the environment:
import soccer_twos
env = soccer_twos.make()The make method accepts several options:
| Option | Description |
|---|---|
render |
Whether to render the environment. Defaults to False. |
watch |
Whether to run an audience-friendly version the provided Soccer-Twos environment. Forces render to True, time_scale to 1 and quality_level to 5. Has no effect when env_path is set. Defaults to False. |
variation |
A soccer env variation in EnvType. Defaults to EnvType.multiagent_player |
blue_team_name |
The name of the blue team. Defaults to "BLUE". |
orange_team_name |
The name of the orange team. Defaults to "ORANGE". |
env_channel |
The side channel to use for communication with the environment. Defaults to None. |
time_scale |
The time scale to use for the environment. This should be less than 100x for better simulation accuracy. Defaults to 20x realtime. |
quality_level |
The quality level to use when rendering the environment. Ranges between 0 (lowest) and 5 (highest). Defaults to 0. |
base_port |
The base port to use to communicate with the environment. Defaults to 50039. |
worker_id |
Used as base port shift to avoid communication conflicts. Defaults to 0. |
env_path |
The path to the environment executable. Overrides watch. Defaults to the provided Soccer-Twos environment. |
flatten_branched |
If True, turn branched discrete action spaces into a Discrete space rather than MultiDiscrete. Defaults to False. |
opponent_policy |
The policy to use for the opponent when variation==team_vs_policy. Defaults to a random agent. |
single_player |
Whether to let the agent control a single player, while the other stays still. Only works when variation==team_vs_policy. Defaults to False. |
The created env exposes a basic Gym interface.
Namely, the methods reset(), step(action: Dict[int, np.ndarray]) and close() are available.
The render() method has currently no effect and soccer_twos.make(render=True) should be used instead.
The step() method returns extra information about the player and the ball in the last tuple element. This extra information includes position (x, y) and velocity (x, y) for the ball and players and y rotation (in degrees) of the players.
We expose an RLLib-compatible multiagent interface.
This means, for example, that action should be a dict where keys are integers in {0, 1, 2, 3} corresponding to each agent.
Additionally, values should be single actions shaped like env.action_space.shape.
Observations and rewards follow the same structure. Dones are only set for the key __all__, which means "all agents".
Agents 0 and 1 correspond to the blue team and agents 2 and 3 correspond to the orange team.
Here's a full example:
import soccer_twos
env = soccer_twos.make(render=True)
print("Observation Space: ", env.observation_space.shape)
print("Action Space: ", env.action_space.shape)
team0_reward = 0
team1_reward = 0
while True:
obs, reward, done, info = env.step(
{
0: env.action_space.sample(),
1: env.action_space.sample(),
2: env.action_space.sample(),
3: env.action_space.sample(),
}
)
team0_reward += reward[0] + reward[1]
team1_reward += reward[2] + reward[3]
if done["__all__"]:
print("Total Reward: ", team0_reward, " x ", team1_reward)
team0_reward = 0
team1_reward = 0
env.reset()The env_channel parameter allows for state configuration inside the simulation. To use it, you must first instantiate a soccer_twos.side_channels.EnvConfigurationChannel and pass it in the soccer_twos.make call. Here's a full example:
import soccer_twos
from soccer_twos.side_channels import EnvConfigurationChannel
env_channel = EnvConfigurationChannel()
env = soccer_twos.make(env_channel=env_channel)
env.reset()
env_channel.set_parameters(
ball_state={
"position": [1, -1],
"velocity": [-1.2, 3],
},
players_states={
3: {
"position": [-5, 10],
"rotation_y": 45,
"velocity": [5, 0],
}
}
)
# env.step()All the env_channel.set_parameters method parameters and dict keys are optional. You can set a single parameter at a time or the full game state if you need so.
To quickly evaluate one agent against another and generate comprehensive statistics, you may use the evaluate script:
python -m soccer_twos.evaluate -m1 agent_module -m2 opponent_module
You can also provide the --episodes option to specify the number of episodes to evaluate on (defaults to 100).
To rollout via CLI, you must create an implementation (subclass) of soccer_twos.AgentInterface and run:
python -m soccer_twos.watch -m agent_module
This will run a human-friendly version of the environment, where your agent will play against itself.
You may instead use the options -m1 agent_module -m2 opponent_module to play against a different opponent.
You may also implement your own rollout script using soccer_twos.make(watch=True).
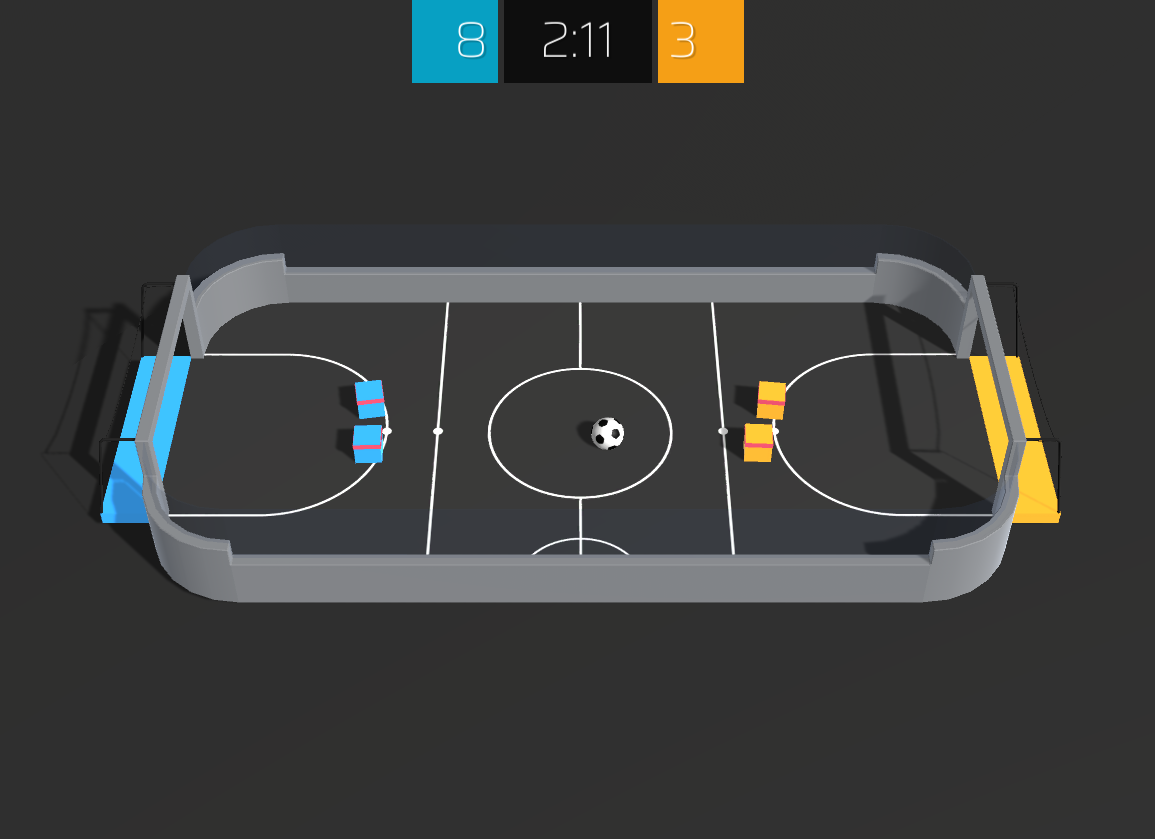
This environment is based on Unity ML Agents' Soccer Twos, so most of the specs are the same. Here, four agents compete in a 2 vs 2 toy soccer game, aiming to get the ball into the opponent's goal while preventing the ball from entering own goal.
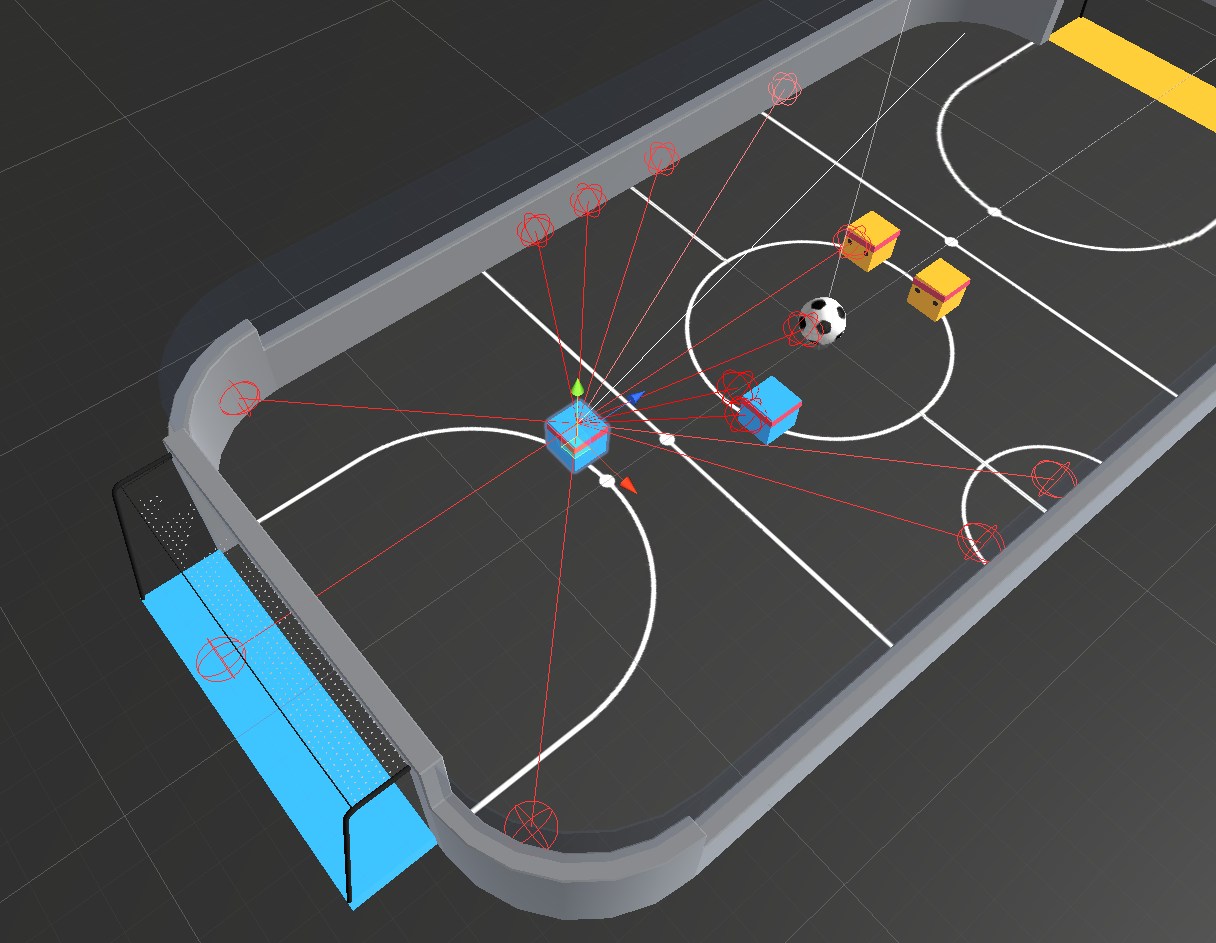
- Observation space: a 336-dimensional vector corresponding to 11 ray-casts forward distributed over 120 degrees and 3 ray-casts backward distributed over 90 degrees, each detecting 6 possible object types, along with the object's distance. The forward ray-casts contribute 264 state dimensions and backward 72 state dimensions over three observation stacks.
- Action space: 3 discrete branched actions (MultiDiscrete) corresponding to forward, backward, sideways movement, as well as rotation (27 discrete actions).
- Agent Reward Function:
1 - accumulated time penalty: when ball enters opponent's goal. Accumulated time penalty is incremented by(1 / MaxSteps)every fixed update and is reset to 0 at the beginning of an episode. In this build,MaxSteps = 5000.-1: when ball enters team's goal.
Note that while this is true when variation == EnvType.multiagent_player, observation and action spaces may vary for other variations.
@misc{soccertwos,
author = {Bryan Oliveira},
title = {A pre-compiled Soccer-Twos reinforcement learning environment with multi-agent Gym-compatible wrappers and human-friendly visualizers.},
year = {2021},
publisher = {GitHub},
journal = {GitHub Repository},
howpublished = {\url{https://github.com/bryanoliveira/soccer-twos-env}}
}