This Actor provides web browsing functionality for AI and LLM applications, similar to the web browsing feature in ChatGPT. It accepts a search phrase or a URL, queries Google Search, then crawls web pages from the top search results, cleans the HTML, converts it to text or Markdown, and returns it back for processing by the LLM application. The extracted text can then be injected into prompts and retrieval augmented generation (RAG) pipelines, to provide your LLM application with up-to-date context from the web.
- 🚀 Quick response times for great user experience
- ⚙️ Supports dynamic JavaScript-heavy websites using a headless browser
- 🕷 Automatically bypasses anti-scraping protections using proxies and browser fingerprints
- 📝 Output formats include Markdown, plain text, and HTML
- 🪟 It's open source, so you can review and modify it
For a search query like web browser site:openai.com, the Actor will return an array with a content of top results from Google Search:
[
{
"metadata": {
"url": "https://python.langchain.com/docs/integrations/providers/apify/#utility",
"title": "Apify | 🦜️🔗 LangChain"
},
"text": "Apify | 🦜️🔗 LangChain | This notebook shows how to use the Apify integration ..."
},
{
"metadata": {
"url": "https://microsoft.github.io/autogen/0.2/docs/notebooks/agentchat_webscraping_with_apify/",
"title": "Web Scraping using Apify Tools | AutoGen"
},
"text": "Web Scraping using Apify Tools | This notebook shows how to use Apify tools with AutoGen agents ...."
}
]If you enter a specific URL such as https://docs.apify.com/platform/integrations/openai-assistants, the Actor will extract
the web page content directly.
[
{
"metadata": {
"url": "https://docs.apify.com/platform/integrations/openai-assistants",
"title": "OpenAI Assistants integration | Platform | Apify Documentation"
},
"text": "OpenAI Assistants integration. Learn how to integrate Apify with OpenAI Assistants to provide real-time search data ..."
}
]The RAG Web Browser can be used in two ways: as a standard Actor by passing it an input object with the settings, or in the Standby mode by sending it an HTTP request.
You can run the Actor "normally" via API or manually, pass it an input JSON object with settings including the search phrase or URL, and it will store the results to the default dataset. This is useful for testing and evaluation, but might be too slow for production applications and RAG pipelines, because it takes some time to start a Docker container and the web browser. Also, one Actor run can only handle one query, which isn't very inefficient.
The Actor also supports the Standby mode, where it runs an HTTP web server that receives requests with the search phrases and responds with the extracted web content. This way is preferred for production applications, because if the Actor is already running, it will return the results much faster. Additionally, in the Standby mode the Actor can handle multiple requests in parallel, and thus utilizes the computing resources more efficiently.
To use RAG Web Browser in the Standby mode, simply send an HTTP GET request to the following URL:
https://rag-web-browser.apify.actor/search?token=<APIFY_API_TOKEN>&query=<QUERY>
where <APIFY_API_TOKEN> is your Apify API token and <QUERY>
is the search query or a single web page URL.
Note that you can also pass the API token using the Authorization HTTP header with Basic authentication for increased security.
The response is a JSON array with objects containing the web content from the found web pages.
The /search GET HTTP endpoint accepts the following query parameters:
| Parameter | Type | Default | Description |
|---|---|---|---|
query |
string | N/A | Enter Google Search keywords or a URL to a specific web page. The keywords might include the advanced search operators. You need to percent-encode the value if it contains some special characters. |
maxResults |
number | 3 |
The maximum number of top organic Google Search results whose web pages will be extracted. If query is a URL, then this parameter is ignored and the Actor only fetches the specific web page. |
outputFormats |
string | markdown |
Select one or more formats to which the target web pages will be extracted. Use comma to separate multiple values (e.g. text,markdown) |
requestTimeoutSecs |
number | 30 |
The maximum time in seconds available for the request, including querying Google Search and scraping the target web pages. For example, OpenAI allows only 45 seconds for custom actions. If a target page loading and extraction exceeds this timeout, the corresponding page will be skipped in results to ensure at least some results are returned within the timeout. If no page is extracted within the timeout, the whole request fails. |
serpProxyGroup |
string | GOOGLE_SERP |
Enables overriding the default Apify Proxy group used for fetching Google Search results. |
serpMaxRetries |
number | 1 |
The maximum number of times the Actor will retry fetching the Google Search results on error. If the last attempt fails, the entire request fails. |
maxRequestRetries |
number | 1 |
The maximum number of times the Actor will retry loading the target web page on error. If the last attempt fails, the page will be skipped in the results. |
requestTimeoutContentCrawlSecs |
number | 30 |
The maximum time in seconds for loading and extracting the target web page content. The value should be smaller than the requestTimeoutSecs setting to have any effect. |
dynamicContentWaitSecs |
number | 10 |
The maximum time in seconds to wait for dynamic page content to load. The Actor considers the web page as fully loaded once this time elapses or when the network becomes idle. |
removeCookieWarnings |
boolean | true |
If enabled, removes cookie consent dialogs to improve text extraction accuracy. Note that this will impact latency. |
debugMode |
boolean | false |
If enabled, the Actor will store debugging information in the dataset's debug field. |
The /search GET HTTP endpoint responds with a JSON array, which looks as follows:
[
{
"crawl": {
"httpStatusCode": 200,
"loadedAt": "2024-09-02T08:44:41.750Z",
"uniqueKey": "3e8452bb-c703-44af-9590-bd5257902378",
"requestStatus": "handled"
},
"searchResult": {
"url": "https://apify.com/",
"title": "Apify: Full-stack web scraping and data extraction platform",
"description": "Cloud platform for web scraping, browser automation, and data for AI...."
},
"metadata": {
"author": null,
"title": "Apify: Full-stack web scraping and data extraction platform",
"description": "Cloud platform for web scraping, browser automation, and data for AI....",
"keywords": "web scraper,web crawler,scraping,data extraction,API",
"languageCode": "en",
"url": "https://apify.com/"
},
"text": "Full-stack web scraping and data extraction platform...",
"markdown": "# Full-stack web scraping and data extraction platform..."
}
]RAG Web Browser has been designed for easy integration to LLM applications, GPTs, assistants, and RAG pipelines using function calling.
Here you can find the OpenAPI schema
for the Standby web server. Note that the OpenAPI definition contains
all available query parameters, but only query is required.
You can remove all the others parameters from the definition if their default value is right for your application,
in order to reduce the number of LLM tokens necessary and to reduce the risk of hallucinations.
While ChatGPT and GPTs supports web browsing natively, OpenAI Assistants do not. With RAG Web Browser, you can easily add the web search and browsing capability to your custom AI assistant and chatbots.
For detailed instructions and a step-by-step guide, see the OpenAI Assistants integration in Apify documentation.
You can easily add the RAG Web Browser to your GPT by creating a custom action using the OpenAPI schema. Follow the detailed guide in the article Add custom actions to your GPTs with Apify Actors.
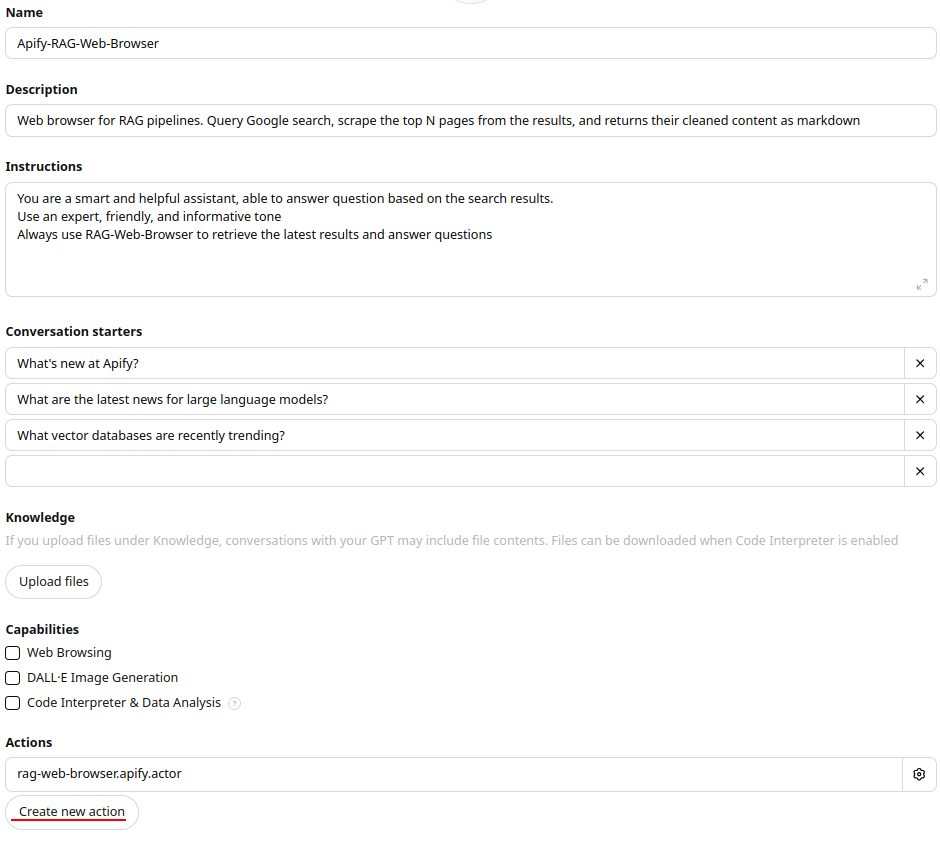
Here's a quick guide to adding the RAG Web Browser to your GPT as a custom action:
- Click on Explore GPTs in the left sidebar, then select + Create in the top right corner.
- Complete all required details in the form.
- Under the Actions section, click Create new action.
- In the Action settings, set Authentication to API key and choose Bearer as Auth Type.
- In the schema field, paste the OpenAPI specification for the RAG Web Browser.
- Normal mode: Copy the OpenAPI schema from the RAG-Web-Browser Actor under the API -> OpenAPI specification.
- Standby mode: Copy the OpenAPI schema from the OpenAPI standby mode json file.
You can set the requestTimeoutSecs parameter to define how long the Actor should spend on making the search request and crawling.
If the timeout is exceeded, the Actor will return whatever results were scraped up to that point.
For example, the following outputs (truncated for brevity) illustrate this behavior:
- The first result from https://github.com/apify was scraped fully.
- The second result from https://apify.com was partially scraped due to the timeout. As a result, only the
googleSearchResultis returned, and in this case, thegoogleSearchResult.descriptionwas copied into thetextfield.
[
{
"crawl": {
"httpStatusCode": 200,
"httpStatusMessage": "OK",
"requestStatus": "handled"
},
"searchResult": {
"description": "Apify command-line interface helps you create, develop, build and run Apify actors, and manage the Apify cloud platform.",
"title": "Apify",
"url": "https://github.com/apify"
},
"text": "Apify · Crawlee — A web scraping and browser automation library for Python"
},
{
"crawl": {
"httpStatusCode": 500,
"httpStatusMessage": "Timed out",
"requestStatus": "failed"
},
"searchResult": {
"description": "Cloud platform for web scraping, browser automation, and data for AI.",
"title": "Apify: Full-stack web scraping and data extraction platform",
"url": "https://apify.com/"
},
"text": ""
}
]To optimize the performance and cost of your application, see the Standby mode settings.
The latency is proportional to the memory allocated to the Actor and number of results requested.
Below is a typical latency breakdown for the RAG Web Browser with maxResults set to either 1 or 3. These settings allow for processing all search results in parallel.
Please note the these results are only indicative and may vary based on the search term, the target websites, and network latency.
The numbers below are based on the following search terms: "apify", "Donald Trump", "boston". Results were averaged for the three queries.
| Memory (GB) | Max Results | Latency (s) |
|---|---|---|
| 4 | 1 | 22 |
| 4 | 3 | 31 |
| 8 | 1 | 16 |
| 8 | 3 | 17 |
Based on your requirements, if low latency is a priority, consider running the Actor with 4GB or 8GB of memory. However, if you're looking for a cost-effective solution, you can run the Actor with 2GB of memory, but you may experience higher latency and might need to set a longer timeout.
For low latency, it's recommended to run the RAG Web Browser with 8 GB of memory. Additionally, adjust these settings to further optimize performance:
- Dynamic Content Wait Secs: Set this to 0 if you don't need to wait for dynamic content. This can significantly reduce latency.
- Remove Cookie Warnings: If the websites you're scraping don't have cookie warnings, set this to false to slightly improve latency.
- Debug Mode: Enable this to store debugging information if you need to measure the Actor's latency.
If you require a response within a certain timeframe, use the requestTimeoutSecs parameter to define the maximum duration the Actor should spend on making search requests and crawling.
The Actor defaults to Google Search in the United States and English language and so queries like "best nearby restaurants" will return search results from the US.
If you need other regions or languages, or have some other feedback, please submit an issue on the Actor in Apify Console to let us know.
The RAG Web Browser Actor has open source on GitHub, so that you can modify and develop it yourself. Here are the steps how to run it locally on your computer.
Download the source code:
git clone https://github.com/apify/rag-web-browser
cd rag-web-browserInstall Playwright with dependencies:
npx playwright install --with-depsAnd then you can run it locally using Apify CLI as follows:
APIFY_META_ORIGIN=STANDBY apify run -p