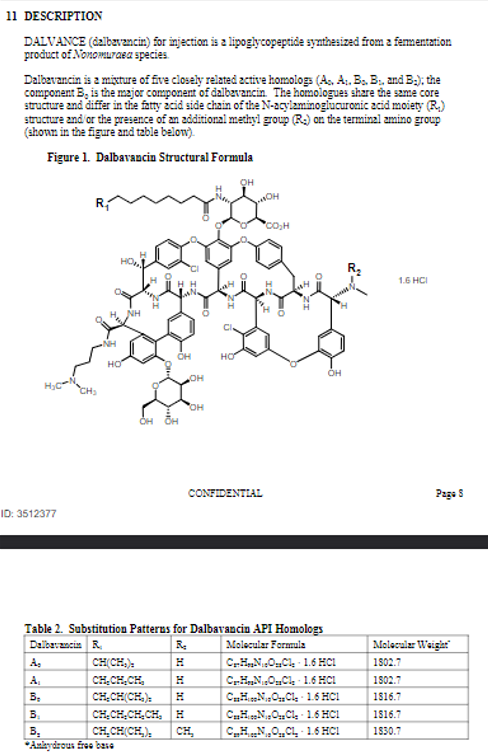
Important
Marker API provides a simple endpoint for converting PDF documents to Markdown quickly and accurately. With just one click, you can deploy the Marker API endpoint and start converting PDFs seamlessly.
- PDF to Markdown Conversion 📄 ➡️ 📝: Converts PDF documents to Markdown efficiently.
- Asynchronous Processing ⏳🔄: Supports both sync and async task processing.
- Distributed Architecture 🌐📡: Enables distributed processing using Celery and Redis.
- Monitoring 📊👁️: Integrated with Flower for monitoring the Celery tasks.
- Scalable 📈🛠️: Easily scalable with distributed workers.
- GPU/CPU Support 💻⚡: Supports both CPU and GPU for intensive processing.
- Multi-Language Support 🌍💬: Handles documents in any language.
- Advanced Formatting 🎨📋: Extracts tables, images, and code blocks accurately.
- Equation Handling ✏️➗: Converts most mathematical equations to LaTeX.
- Docker and Kubernetes Support 🐳🛠️: Full Docker support for both CPU and GPU setups, and Kubernetes (coming soon).
| Original PDF | Marker-API | PyPDF |
|---|---|---|
 |
 |
 |
Here’s an improved version of the features section, along with the comparison table and setup details:
| Criteria | Simple Server | Distributed Server |
|---|---|---|
| Use Case | Small scale, local deployments | Large scale, production environments |
| Scalability | Limited (single server) | Highly scalable with multiple workers |
| Performance | Synchronous (one file at a time) | Asynchronous with parallel task processing |
| Setup Complexity | Easy (local or Docker setup) | Moderate (multiple services to manage) |
| Monitoring | No built-in monitoring | Flower for task monitoring |
| Failure Tolerance | Low (single server) | High (distributed worker nodes) |
| Docker Support | Yes, CPU and GPU | Yes, CPU and GPU |
| Resource Utilization | Limited to local resources | Efficient resource distribution with Celery |
| Task Distribution | No task distribution | Uses Celery for task distribution |
| Ideal For | Testing, small local deployments | Production environments with high traffic |
-
Clone the repository:
git clone https://github.com/adithya-s-k/marker-api cd marker-api -
Set up the Python environment:
cp .env.example .env poetry install # or pip install -e .
-
Run the server:
python server.py --host 0.0.0.0 --port 8080
-
For CPU:
docker build -f docker/Dockerfile.cpu.server -t marker-api-cpu . docker run -p 8080:8080 marker-api-cpu -
For GPU:
docker build -f docker/Dockerfile.gpu.server -t marker-api-gpu . docker run --gpus all -p 8080:8080 marker-api-gpu
The distributed server setup uses several services like FastAPI, Redis, Celery workers, and Flower, which are designed for large-scale deployments. You can either set it up locally or use Docker Compose for more seamless scaling.
git clone https://github.com/adithya-s-k/marker-api
cd marker-api
cp .env.example .env
poetry install # or
pip install -e .Since Redis is essential for Celery to function, let's run Redis in a Docker container. This will ensure it's up and running on port 6379.
docker run -d -p 6379:6379 redisNow, update your .env file with the correct Redis host URL:
REDIS_HOST=redis://localhost:6379/0You will need three separate terminals for Redis, Celery, and FastAPI:
-
Terminal 1: Start a Celery worker
celery -A marker_api.celery_worker.celery_app worker --pool=solo --loglevel=info
-
Terminal 2: Start Flower for Celery task monitoring
celery -A marker_api.celery_worker.celery_app flower --port=5555
-
Terminal 3: Run FastAPI server
python distributed_server.py --host 0.0.0.0 --port 8080
To scale Celery workers manually, you can open more terminals and run the same Celery worker command:
celery -A marker_api.celery_worker.celery_app worker --pool=solo --loglevel=infoEach new terminal will spin up a new worker, allowing the system to handle more tasks concurrently.
For an even more seamless setup, you can use Docker Compose, which helps run all services within containers. Here’s how to do it.
Use Docker Compose to orchestrate all the services.
-
Without Scaling:
sudo docker-compose -f docker-compose.gpu.yml up --build
This command will start:
- FastAPI on port 8080.
- Redis for managing task queue messages.
- Celery Worker to handle background tasks.
- Flower on port 5556 to monitor the Celery tasks.
To scale up Celery workers, you can use the --scale option:
sudo docker-compose -f docker-compose.gpu.yml up --build --scale celery_worker=3- This command will start 3 Celery workers, increasing the task processing capacity of the system.
- When you use scaling, Docker Compose will automatically spin up multiple instances of the
celery_workerservice.
When running without scaling, you get one instance of the Celery worker service. However, adding the --scale celery_worker=3 flag creates three instances of the worker, meaning tasks will be processed concurrently by three separate workers, which improves the throughput and helps distribute the load across multiple workers.
(Coming Soon)
The distributed server architecture offers several advantages over the simple server:
-
Scalability: By using Celery workers, the system can easily scale horizontally by adding more worker instances to handle increased load.
-
Reliability: The distributed system is more resilient to failures. If one worker crashes, others can continue processing tasks.
-
Non-blocking: Asynchronous processing allows the API to handle many requests concurrently without blocking, improving overall throughput.
-
Resource Management: The distributed architecture allows for better management of resources, particularly important for GPU utilization in PDF processing.
-
Monitoring: With tools like Flower, it's easier to monitor the system's performance and identify bottlenecks.
-
Flexibility: The distributed setup allows for more complex workflows and integration with other services.
By using the distributed server, you can process multiple PDFs in parallel, handle high loads more effectively, and provide a more responsive service to your users.
Marker converts PDF to markdown quickly and accurately.
- Supports a wide range of documents (optimized for books and scientific papers)
- Supports all languages
- Removes headers/footers/other artifacts
- Formats tables and code blocks
- Extracts and saves images along with the markdown
- Converts most equations to latex
- Works on GPU, CPU, or MPS
Marker is a pipeline of deep learning models:
- Extract text, OCR if necessary (heuristics, surya, tesseract)
- Detect page layout and find reading order (surya)
- Clean and format each block (heuristics, texify
- Combine blocks and postprocess complete text (heuristics, pdf_postprocessor)
It only uses models where necessary, which improves speed and accuracy.
| Type | Marker | Nougat | |
|---|---|---|---|
| Think Python | Textbook | View | View |
| Think OS | Textbook | View | View |
| Switch Transformers | arXiv paper | View | View |
| Multi-column CNN | arXiv paper | View | View |

The above results are with marker and nougat setup so they each take ~4GB of VRAM on an A6000.
See below for detailed speed and accuracy benchmarks, and instructions on how to run your own benchmarks.
I want marker to be as widely accessible as possible, while still funding my development/training costs. Research and personal usage is always okay, but there are some restrictions on commercial usage.
The weights for the models are licensed cc-by-nc-sa-4.0, but I will waive that for any organization under $5M USD in gross revenue in the most recent 12-month period AND under $5M in lifetime VC/angel funding raised. If you want to remove the GPL license requirements (dual-license) and/or use the weights commercially over the revenue limit, check out the options here.
Discord is where we discuss future development.
PDF is a tricky format, so marker will not always work perfectly. Here are some known limitations that are on the roadmap to address:
- Marker will not convert 100% of equations to LaTeX. This is because it has to detect then convert.
- Tables are not always formatted 100% correctly - text can be in the wrong column.
- Whitespace and indentations are not always respected.
- Not all lines/spans will be joined properly.
- This works best on digital PDFs that won't require a lot of OCR. It's optimized for speed, and limited OCR is used to fix errors.
You'll need python 3.9+ and PyTorch. You may need to install the CPU version of torch first if you're not using a Mac or a GPU machine. See here for more details.
Install with:
pip install marker-pdfOnly needed if you want to use the optional ocrmypdf as the ocr backend. Note that ocrmypdf includes Ghostscript, an AGPL dependency, but calls it via CLI, so it does not trigger the license provisions.
See the instructions here
First, some configuration:
- Inspect the settings in
marker/settings.py. You can override any settings with environment variables. - Your torch device will be automatically detected, but you can override this. For example,
TORCH_DEVICE=cuda.- If using GPU, set
INFERENCE_RAMto your GPU VRAM (per GPU). For example, if you have 16 GB of VRAM, setINFERENCE_RAM=16. - Depending on your document types, marker's average memory usage per task can vary slightly. You can configure
VRAM_PER_TASKto adjust this if you notice tasks failing with GPU out of memory errors.
- If using GPU, set
- By default, marker will use
suryafor OCR. Surya is slower on CPU, but more accurate than tesseract. If you want faster OCR, setOCR_ENGINEtoocrmypdf. This also requires external dependencies (see above). If you don't want OCR at all, setOCR_ENGINEtoNone.
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10 --langs English--batch_multiplieris how much to multiply default batch sizes by if you have extra VRAM. Higher numbers will take more VRAM, but process faster. Set to 2 by default. The default batch sizes will take ~3GB of VRAM.--max_pagesis the maximum number of pages to process. Omit this to convert the entire document.--langsis a comma separated list of the languages in the document, for OCR
Make sure the DEFAULT_LANG setting is set appropriately for your document. The list of supported languages for OCR is here. If you need more languages, you can use any language supported by Tesseract if you set OCR_ENGINE to ocrmypdf. If you don't need OCR, marker can work with any language.
marker /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000--workersis the number of pdfs to convert at once. This is set to 1 by default, but you can increase it to increase throughput, at the cost of more CPU/GPU usage. Parallelism will not increase beyondINFERENCE_RAM / VRAM_PER_TASKif you're using GPU.--maxis the maximum number of pdfs to convert. Omit this to convert all pdfs in the folder.--min_lengthis the minimum number of characters that need to be extracted from a pdf before it will be considered for processing. If you're processing a lot of pdfs, I recommend setting this to avoid OCRing pdfs that are mostly images. (slows everything down)--metadata_fileis an optional path to a json file with metadata about the pdfs. If you provide it, it will be used to set the language for each pdf. If not,DEFAULT_LANGwill be used. The format is:
{
"pdf1.pdf": {"languages": ["English"]},
"pdf2.pdf": {"languages": ["Spanish", "Russian"]},
...
}
You can use language names or codes. The exact codes depend on the OCR engine. See here for a full list for surya codes, and here for tesseract.
MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_outMETADATA_FILEis an optional path to a json file with metadata about the pdfs. See above for the format.NUM_DEVICESis the number of GPUs to use. Should be2or greater.NUM_WORKERSis the number of parallel processes to run on each GPU. Per-GPU parallelism will not increase beyondINFERENCE_RAM / VRAM_PER_TASK.MIN_LENGTHis the minimum number of characters that need to be extracted from a pdf before it will be considered for processing. If you're processing a lot of pdfs, I recommend setting this to avoid OCRing pdfs that are mostly images. (slows everything down)
Note that the env variables above are specific to this script, and cannot be set in local.env.
There are some settings that you may find useful if things aren't working the way you expect:
OCR_ALL_PAGES- set this to true to force OCR all pages. This can be very useful if the table layouts aren't recognized properly by default, or if there is garbled text.TORCH_DEVICE- set this to force marker to use a given torch device for inference.OCR_ENGINE- can set this tosuryaorocrmypdf.DEBUG- setting this toTrueshows ray logs when converting multiple pdfs- Verify that you set the languages correctly, or passed in a metadata file.
- If you're getting out of memory errors, decrease worker count (increased the
VRAM_PER_TASKsetting). You can also try splitting up long PDFs into multiple files.
In general, if output is not what you expect, trying to OCR the PDF is a good first step. Not all PDFs have good text/bboxes embedded in them.
Benchmarking PDF extraction quality is hard. I've created a test set by finding books and scientific papers that have a pdf version and a latex source. I convert the latex to text, and compare the reference to the output of text extraction methods. It's noisy, but at least directionally correct.
Benchmarks show that marker is 4x faster than nougat, and more accurate outside arXiv (nougat was trained on arXiv data). We show naive text extraction (pulling text out of the pdf with no processing) for comparison.
Speed
| Method | Average Score | Time per page | Time per document |
|---|---|---|---|
| marker | 0.613721 | 0.631991 | 58.1432 |
| nougat | 0.406603 | 2.59702 | 238.926 |
Accuracy
First 3 are non-arXiv books, last 3 are arXiv papers.
| Method | multicolcnn.pdf | switch_trans.pdf | thinkpython.pdf | thinkos.pdf | thinkdsp.pdf | crowd.pdf |
|---|---|---|---|---|---|---|
| marker | 0.536176 | 0.516833 | 0.70515 | 0.710657 | 0.690042 | 0.523467 |
| nougat | 0.44009 | 0.588973 | 0.322706 | 0.401342 | 0.160842 | 0.525663 |
Peak GPU memory usage during the benchmark is 4.2GB for nougat, and 4.1GB for marker. Benchmarks were run on an A6000 Ada.
Throughput
Marker takes about 4.5GB of VRAM on average per task, so you can convert 10 documents in parallel on an A6000.

You can benchmark the performance of marker on your machine. Install marker manually with:
git clone https://github.com/VikParuchuri/marker.git
poetry installDownload the benchmark data here and unzip. Then run benchmark.py like this:
python benchmark.py data/pdfs data/references report.json --nougatThis will benchmark marker against other text extraction methods. It sets up batch sizes for nougat and marker to use a similar amount of GPU RAM for each.
Omit --nougat to exclude nougat from the benchmark. I don't recommend running nougat on CPU, since it is very slow.
This work would not have been possible without amazing open source models and datasets, including (but not limited to):
- Surya
- Texify
- Pypdfium2/pdfium
- DocLayNet from IBM
- ByT5 from Google
Thank you to the authors of these models and datasets for making them available to the community!
- Create server
- Add support for single PDF upload
- Add support for multi PDF upload
- Docker support and Skypilot support
- Implement handling for multiple PDF uploads simultaneously.
- Introduce a toggle mode to generate Markdown without including images in the output.
- Enhance GPU utilization and optimize performance for efficient processing.
- Implement dynamic adjustment of batch size based on available VRAM.
- Add celery and flower for distributed queue and monitoring
- Locust for load testing
- Distibuted server for scaling workloads
- Clinet package init
- add K8s and helm chart
- Benchmarks from production load testing
Marker-api is licensed under the GPL-3.0 license. See LICENSE for more information.
The project uses Marker under the hood, which has a commercial license that needs to be followed. Here are the details:
Marker and Surya OCR Models are designed to be as widely accessible as possible while still funding development and training costs. Research and personal usage are always allowed, but there are some restrictions on commercial usage. The weights for the models are licensed under cc-by-nc-sa-4.0. However, this restriction is waived for any organization with less than $5M USD in gross revenue in the most recent 12-month period AND less than $5M in lifetime VC/angel funding raised. To remove the GPL license requirements (dual-license) and/or use the weights commercially over the revenue limit, check out the options provided. Please refer to Marker for more Information about the License of the Model weights
This project is a fork of marker project created by VikParuchuri.