Termslens is a python-based software built on a powerful algorithm capable of analysing dubious general terms and conditions of use and extracting, using a large volume of training data, any suspicious content in the terms and conditions that could affect the user's privacy and anonymty.

- Installing and running
- How to make TermsLens work and how it works
- Algorithm
- Non-liability clause, credits and license
TermsLens is an educational tool designed for school, research and learning purposes. It serves to demonstrate text analysis techniques and should not be relied upon as a sole means for critical decision-making. By using this software, you acknowledge and agree:
- Educational Purpose: TermsLens is intended for educational purposes ONLY. It is not a substitute for professional advice or analysis.
- No Warranty: There is no warranty, implied or explicit, regarding the accuracy, reliability, or completeness of the results generated by TermsLens.
- User Responsibility: Users are solely responsible for their use of this tool and any decisions made based on its output.
- Limited Liability: The author and contributors of TermsLens are not liable for any direct or indirect damages, losses, or inconvenience resulting from the use of this software.
- Not Legal Advice: The analysis provided by TermsLens does not constitute legal advice. Consult legal experts for interpreting legal documents and contracts.
By using this software, you agree that the author and contributors shall not be held liable for any consequences resulting from the use or misuse of this tool. Users are encouraged to use their judgment and seek professional advice when dealing with legal or critical matters. For more information about the disclaimer, credits and licence, please go to the bottom of the page.
Note: I haven't had time to compile my software yet. If you just want to get it working, you will need to check that python3 is installed on your computer, that the modules mentioned below are also installed, then download the files from the github repository to your computer, then run the termslens_gui.py file. (The data.csv and interface.kv file must be in the same directory as termslens_gui.py for this to work)
Launch the graphical interface by executing:
python termslens_gui.pyor
python3 termslens_gui.pyThe interface will provide options to perform operations like selecting a PDF file for analysis, classifying text, and testing the algorithm.
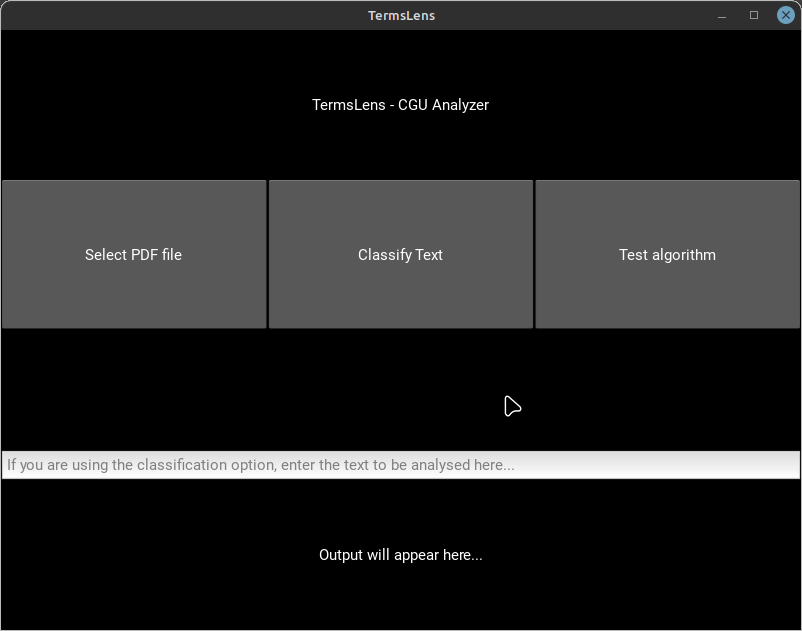
- Select PDF file: Opens a file manager to choose a PDF document for analysis.
- Classify Text: Analyzes the provided text in the horizontal bar below the buttons to determine its suspicious nature.
- Test Algorithm: Evaluates and test the algorithm's performance based on the provided dataset. 75% of the dataset will be used to train the algorithm, and 25% will be used to test it.
As a reminder, TermsLens is a Python-based application that serves the purpose of analyzing dubious general terms and conditions of use contracts to identify potentially privacy-concerning content. It comprises two primary modules: termslens_terminal.py designed for terminal use and easier comprehension of the algorithm, and termslens_gui.py featuring a graphical user interface for a more user-friendly experience. The data.csv file contains the training data that the algorithm uses each time to analyse a file. It must always be in the same directory as the python file you are running. This training data will probably be updated regularly to improve the algorithm, so be sure to come and have a look from time to time!
TermsLens utilizes several Python libraries that need to be installed:
nltkmatplotlibwordcloudPyPDF2pandasnumpykivykivymd
Install these libraries using the following command:
pip install nltk matplotlib wordcloud PyPDF2 pandas numpy kivy kivymdtermslens_terminal.py: Contains the terminal-based version of the application, designed for easy algorithm comprehension.termslens_gui.py: Includes the graphical user interface for a more interactive experience.data.csv: Contains the training data required for the algorithm.interface.kv: Contains the GUI code fortermslens_gui.py.
Run the terminal-based version of TermsLens using the command:
python termslens_terminal.pyor
python3 termslens_terminal.pyFollow the instructions prompted in the terminal to perform various operations like analyzing text, testing the algorithm, etc.
To operate, termslens works as follows in its code (more precisely in termslens_terminal.py):
- Reading the specified pdf file
- Open and read the
data.csvfile - Train and test on the
data.csvfile
Once these steps have been completed:
- Reading the specified pdf file
- Separate the pdf file into lines of text
- Analyse each line of text in detail using the algorithm trained on the dataset
- Filter lines deemed suspicious and return them to the user.
Briefly and more concretely, the general algorithmic operation of Termslens is divided into these three steps:
- Data Preprocessing: Tokenization, removing stop words, stemming, and processing messages.
- Training: Splitting the data into training and testing sets.
- Classification: Analyzing input text or PDF files to identify suspicious content based on the trained model.
These steps can also be observed in the code. Let's now look at the most interesting part, the algorithm, which is the heart of this software:
To achieve its objective, this software uses the Naive Bayes classifier, which is based on the Bayes' theorem. I'll explain in more detail how all this works a little later, but for now, let's analyse the Bayes' theorem formula to better understand what we're talking about:
Pr(A|B) = Pr(B|A) . Pr(A) / Pr(B)
It sounds complicated at first glance, but don't worry, we're going to put this mathematical formula into words: When Termslens reads a sentence(B), the probability that it will be deemed suspicious(A) is equal to the probability that a suspicious sentence(A) is present in the database, multiplied by the probability of having a suspicious sentence in general, divided by the probability of getting a neutral sentence(B) at all.
In other words:
when a sentence is analysed:
pobability to be a suspicious sentence = probability of a suspicious sentence being in the database . probability of having a suspect sentence in a real situation / probability of a sentence being analysed
Do you get it? If it's still abstract, that's normal, don't worry, it's a very complicated subject!
Based on this, we're going to work out the probabilities of words appearing in a sentence: If the word "spaghetti" appears more frequently in the training database, the probability that a sentence named "spaghetti" will be considered suspicious by the algorithm increases considerably.
To train the algorithm in this way, we're going to use another formula, which I'll illustrate very simply here:
P(suspicious word | suspicious sentence) = (number of times the word appears in the database) / total number of words in the suspicious sentences
Next, we're going to use yet another method to calculate the IDF, which adds more dimension to our programme: if, for example, the word spaghetti is also contained in the neutral sentences, its suspicious value will drop. Here's the algorithm illustrated:
IDF(x) = number of messages / number of messages containing the word x.
The formulas shown here are not written as they appear in the python file, but all the code is commented out, so I invite you to have a look at it for yourself!
By the way, I'm sorry if I wasn't concrete enough on this part, I'm not used to explaining such complex subjects in a concrete way, I've got some work to do on that XD
And if you have any suggestions for improvement, I'd love to hear from you! :D
The algorithm utilizes the following libraries:
nltk: For text preprocessing and tokenization.PyPDF2: For extracting text from PDF files.- Other standard libraries for general operations.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
THE CREATORS AND CONTRIBUTORS SHALL NOT BE LIABLE FOR ANY DAMAGES OR LIABILITIES ARISING FROM THE USE, MISUSE, OR INABILITY TO USE THIS SOFTWARE.
YOU USE THIS PROJECT AT YOUR OWN RISK, AND YOU'VE BEEN WARNED!
I'd especially like to thank the authors of this book, which taught me a lot about how artificial intelligence algorithms work in Python, particularly by providing concrete examples and easy-to-remember formulas. I would have had a lot of trouble building my tool without this book.
Any similarity (especially in the data.csv file, which contains a very large volume of text) with something that exists elsewhere (e.g. licensing terms or something similar) would be an incredible coincidence.
If you have a problem with something, my contact page is at the bottom of this page. I will get back to you as soon as possible.
Unless otherwise stated, the code for this project is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
You can contact me for any problem via my contact page.