🐦 Twitter • 📄 Arxiv • 🤗 Datasets
🔗 Multimodal CodeGen for Web Data Extraction
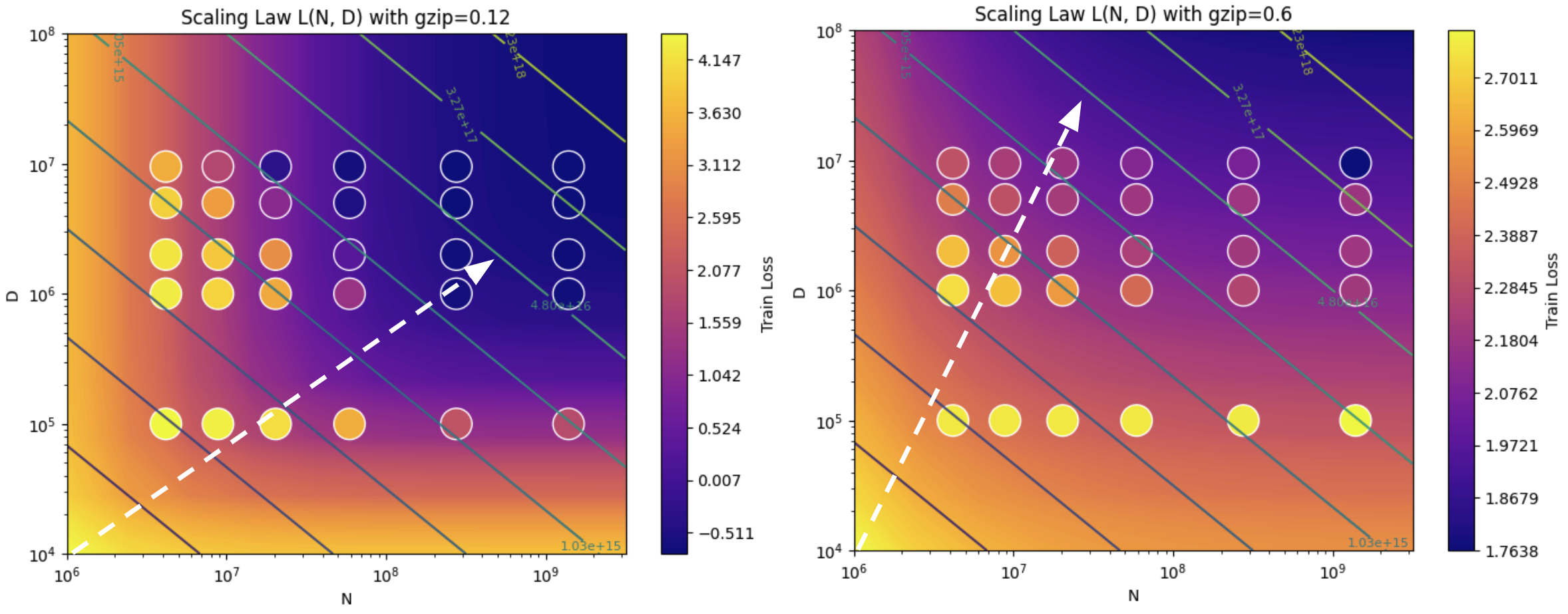
This is the official code for gzip Predicts Data-dependent Scaling Laws (under review at NeurIPS 2024).
We find that:
- scaling laws are sensitive to differences in data complexity
gzip, a compression algorithm, is an effective predictor of how data complexity impacts scaling properties
Our data-dependent scaling law's compute-optimal frontier increases in dataset size preference (over parameter count preference) as training data becomes more complex (harder to compress).
data_gen.py: create PCFGs with specified syntactic properties and sample text datasets from themdata_utils.py:gzip-compressibility measurement, tokenization & HuggingFace tooling, dataloaders, etc.training.py: run a single training run given model and dataset, returning loss at each train stepmain.py: run a set of training runs across datasets & model sizes (hackily GPU-parallelized with threading)fsdp_training.py: for running bigger jobs with cleaner data loading & FSDP training
Upon request via email, we can also provide:
- JSONL records of all training runs (this is large and can't fit on GitHub)
- the Jupyter Notebook used to fit scaling laws from training runs and generate all visuals