此篇是要介紹 HorizontalPodAutoscaler (HPA) 的原理以及實作內容,那我們先來說明一下 HorizontalPodAutoscaler 是什麼吧!
HorizontalPodAutoscaler (HPA) 中文可以叫水平 Pod 自動擴縮,他會自動更新工作負載資源 (Deployment 或 StatefulSet),其目的是透過自動擴縮工作負載來滿足使用需求。
簡單來說他會根據你現在的負載去調整你的 Pod 數量,當目前的負載超過配置的設定時,HPA 會指示工作負載資源 (Deployment 或 StatefulSet) 擴增,來避免塞爆同一個負載資源。
如果負載減少,且 Pod 數量高於配置的最小值,HPA 也會指示工作負載資源 (Deployment 或 StatefulSet) 慢慢縮減。其中水平 Pod 自動擴縮不適用 DaemonSet 工作負載資源。
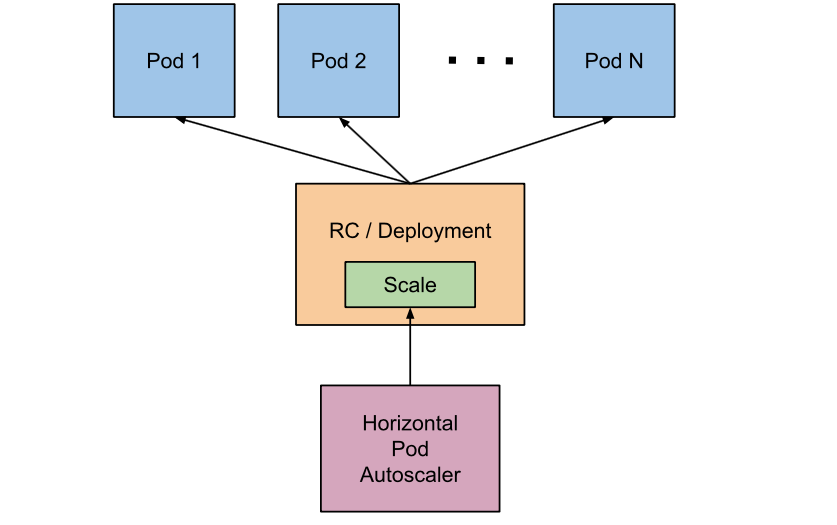
Kubernetes 將水平 Pod 自動擴縮定義為一個間歇運行的控制迴路,他不是連續的,其間隔是由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 參數來配置,預設是 15 秒,controller-manager 會依據每一個 HPA 定義的 scaleTargetRef 來找到是哪一個工作負載資源需要進行水平 Pod 自動擴縮,然後根據目標資源的 .spec.selector 標籤選擇對應的 Pod,並從資源指標 API 或自定義指標獲取 API,目前總共有三種的資源指標,分別是 CPU、Memory、自定義指標。
有關於其他 Kubernetes 觀念部分,可以先查看:
- Kubernetes : Kubernetes (K8s) 介紹 - 基本
- kubernetes : Kubernetes (K8s) 介紹 - 進階 (Service、Ingress、StatefulSet、Deployment、ReplicaSet、ConfigMap)
此文章程式碼也會同步到 Github ,需要的也可以去 clone 使用歐!要記得先確定一下自己的版本 Github 程式碼連結 😆
- macOS:11.6
- Minikube:v1.25.2
- Kubectl:Client Version:v1.24.1、Server Version:v1.23.3
- Metrics Server 3.8.2
這次實作要使用的叢集是 Minikube,所以照以前文章一樣,我們先啟動 Minikube。本次會使用 K8s 的管理工具:k8slens 來做為輔助,大家有興趣也可以先去下載來使用歐 😘
- 啟動 Minikube 叢集
minikube start --vm-driver=docker
由於我們 HorizontalPodAutoscaler 會根據現在的負載來判斷是否要新增新的 Pod 來解決負載資源用完的問題,所以第一個條件就是要先獲的目前的負載資源使用量,這時候我們必須先在 K8s 叢集上安裝 Metrics Server,透過他讓我們可以知道目前的負載使用量!
-
先到 kubernetes-sigs/metrics-server 下載最新的 components.yaml 檔案下來,以我這次示範的版本為例,大家可以點我下載 👇
-
下載完,需要先修改兩個地方,才能 apply 到 Minikube 叢集,第一個是修改
kubelet-preferred-address-types=InternalIP,以及新增kubelet-insecure-tls=ture讓 Metrics Server 禁用 TLS 證書驗證,詳細可以參考以下照片:

- 接著 apply 這個 yaml 檔案:
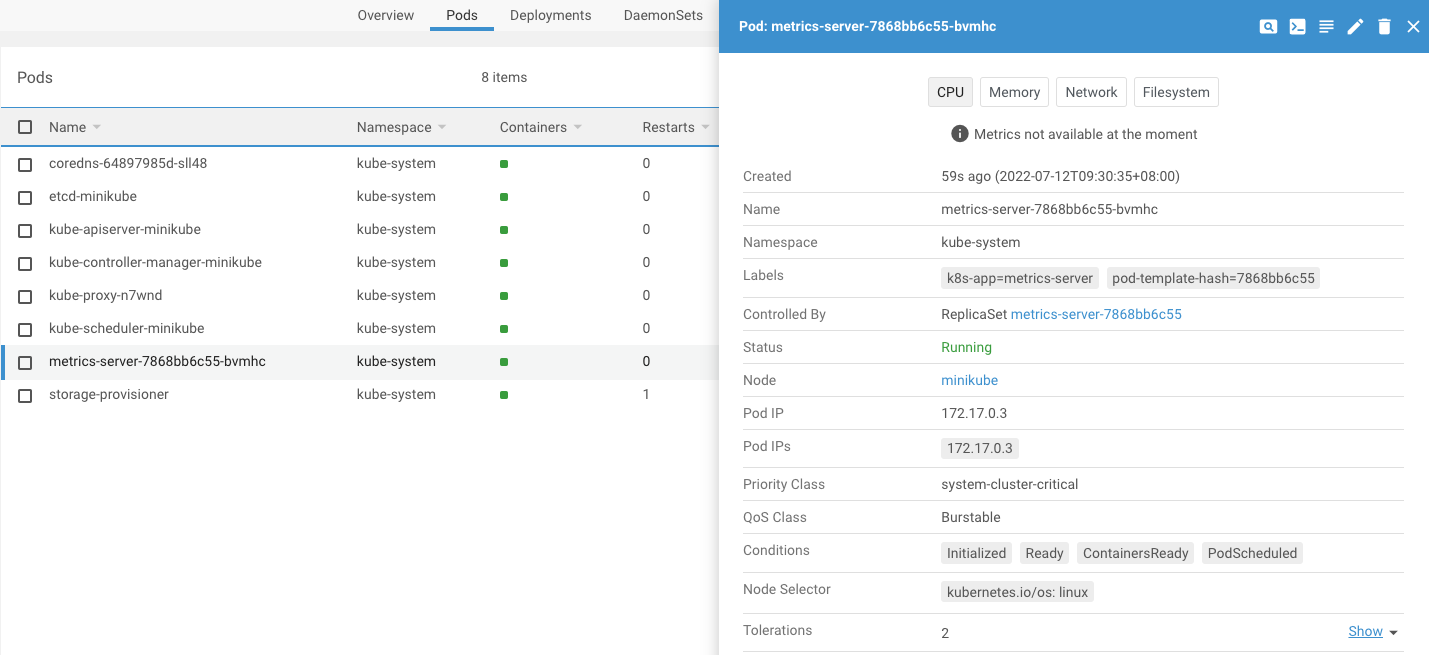
可以檢查一下 deployment.apps/metrics-server 是否有成功建立或是 Pod 是否有問題:
- 接著我們就依照官方的 HorizontalPodAutoscaler Walkthrough 的文章開始囉!首先先寫一個 index.php,這個檔案是用於後續測試 HPA 負載使用量的程式:
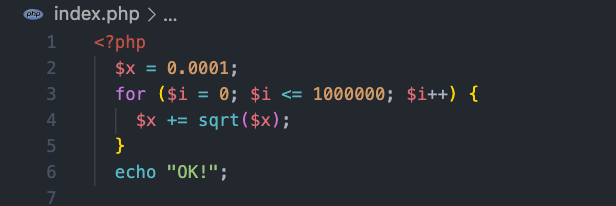
- 新增 Dockerfile,我們使用 php:5-apache 的 image,並複製剛剛寫的 index.php 到容器內:
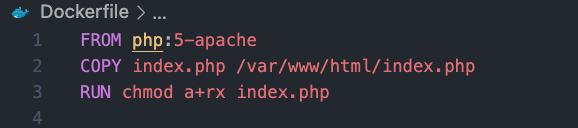
- 將該 Dockerfile Build 起來,推到 DockerHub 上,這部分就不多說明,有興趣可以參考以前文章,大家可以直接使用 880831ian/php-apache 我推好的 image 來使用。
- 新增 Deployment.yaml,裡面會使用我們剛剛打包推到 DockerHub 上的 image:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: 880831ian/php-apache
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
這邊大家可以先記得我們在 containers.resources 有設定 cpu 的 requests 為 200m。後續在計算副本數時會再提到 😬
- 最後將 Deployment.yaml 給 apply,檢查一下是否有正常啟動:
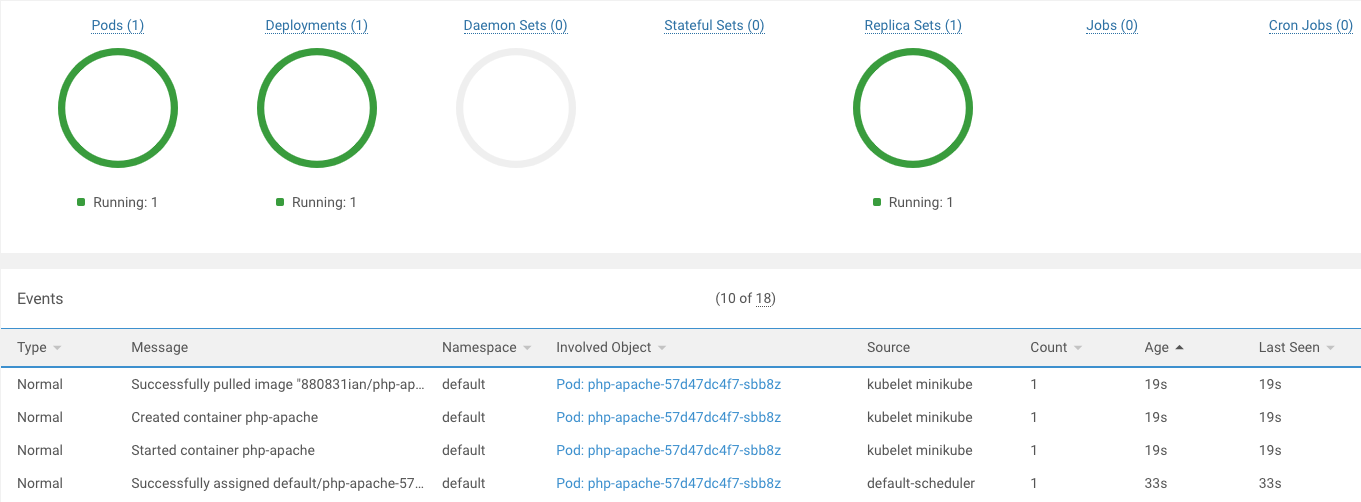
- 使用
kubectl autoscale來幫助我們創建 HorizontalPodAutoscaler:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
這邊特別拉出來說明一下
我們在 Deployment.yaml 裡面 containers.resources 有設定 cpu 的 requests 是 200m,也就是 200 milli-cores,當我們現在設定 HPA 的平均 CPU 使用率為 50%,所以我們只要超過 200m / 2 = 100m,也就是 requests 超過 100 milli-cores 就會產生新的 Pod。這邊最少 Pod 為 1,最多為 10。後續等測試時,會帶大家計算他是如何產生 Pod 的 😏
- 查看目前 HPA 使用量,因為我們這個 php-apache 還沒有任何的訪問,所以是 0% / 50% (承上面所說,所以這邊的值是 0 / 100 milli-cores),後面也可以看到我們所設定最高跟最低的 Pod,以及目前的副本數。

- 當然我們除了用剛剛的指令以外,我們也可以自己寫 HPA 的 yaml 檔案。我這邊先使用
kubectl get hpa php-apache -o yaml > hpa.yaml來將剛剛用指令 run 起來的 HPA 變成 yaml 檔,我們來看看裡面有哪些內容吧:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2022-07-12T03:16:11Z"
name: php-apache
namespace: default
resourceVersion: "19454"
uid: dde68e68-9b6e-46a8-b50f-5525b8ec3bdf
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
後面狀態省略....
- apiVersion:要記得使用
autoscaling/v2 - kind:HorizontalPodAutoscaler
- maxReplicas:是我們剛剛用指令的最大 Pod 副本數
- metrics:我們指標設定 cpu resource,其設定平均使用率為 50 % (百分比)
- minReplicas:剛剛用指令的最小 Pod 副本數
- scaleTargetRef:設定我們這個 HPA 是依照 php-apache 這個 Deployment。
- 接下來我們都設定好後,我們要來模擬增加負載,看看 HPA 的後續動作,首先我們先使用以下指令來持續觀察 HPA:
kubectl get hpa php-apache --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 4h40m
- 以及執行以下指令,該指令是建一個新的 Pod,由新的 Pod 無限循環的去向 php-apahe 服務發出請求
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
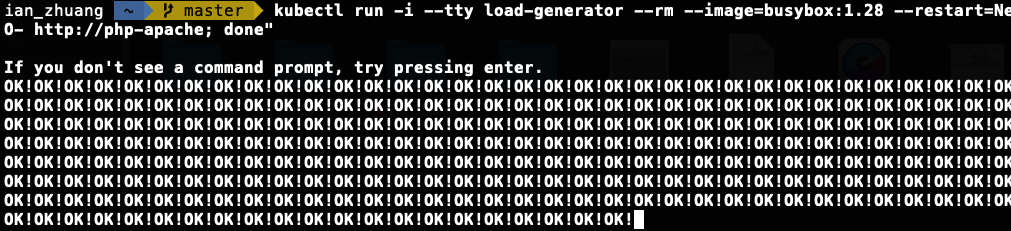
- 我們使用 k8slens 觀察,會發現當負載使用量超過我們前面所設定的 50%,也就是 100 milli-cores 時,他就會自動長新的 Pod 出來:
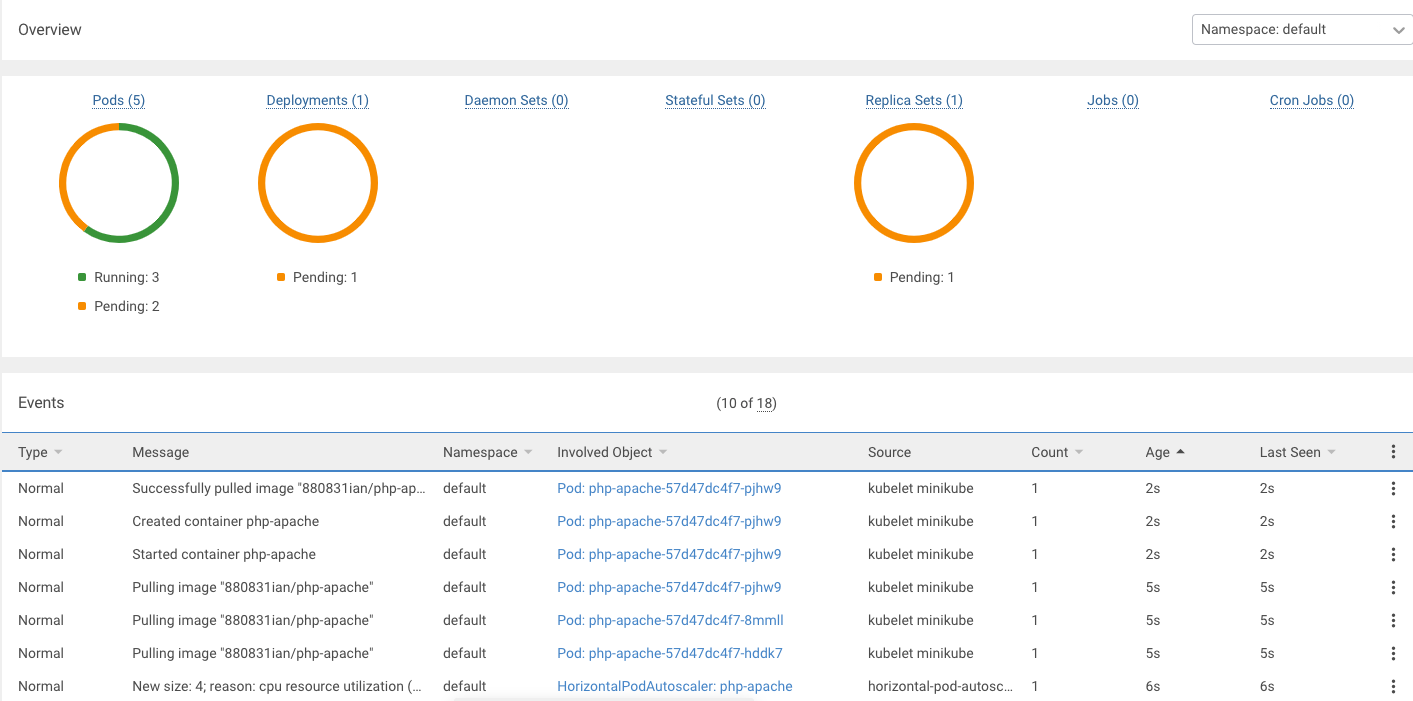
- 我們切回去看觀察 HPA 指令
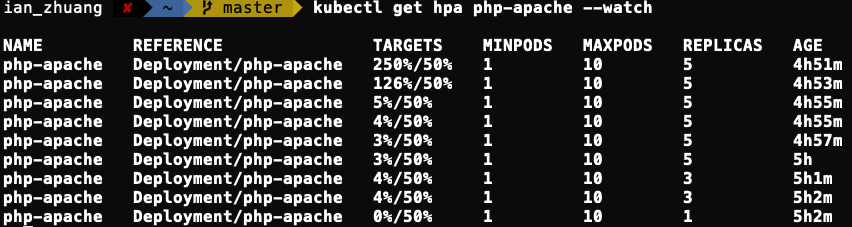
kubectl get hpa php-apache --watch:

如何計算要使用幾個副本
我們剛剛有說超過 50%,也就是 100 milli-cores 時,會長新的 Pod。我們以上面圖片的來說明,來計算期望需要幾個副本?
官方有提供一個公式: 期望副本数 = ceil[目前副本数 * (目前指標 / 期望指標)] ,可以看到我們負載從 0% 從到 250%,也就是我們實際上是從 0 變成 500 milli-cores (250 / 50 * 100 )。
我們將值帶入公式內,目前的副本:1 * (目前指標:500 / 期望指標是:100) 得出來的值是 5,如果有小數,因為前面有 ceil,所以會取整數(不可能開半個 Pod 對吧 🙄),最後以這個例子來說,最終得到的 期望副本数 = 5
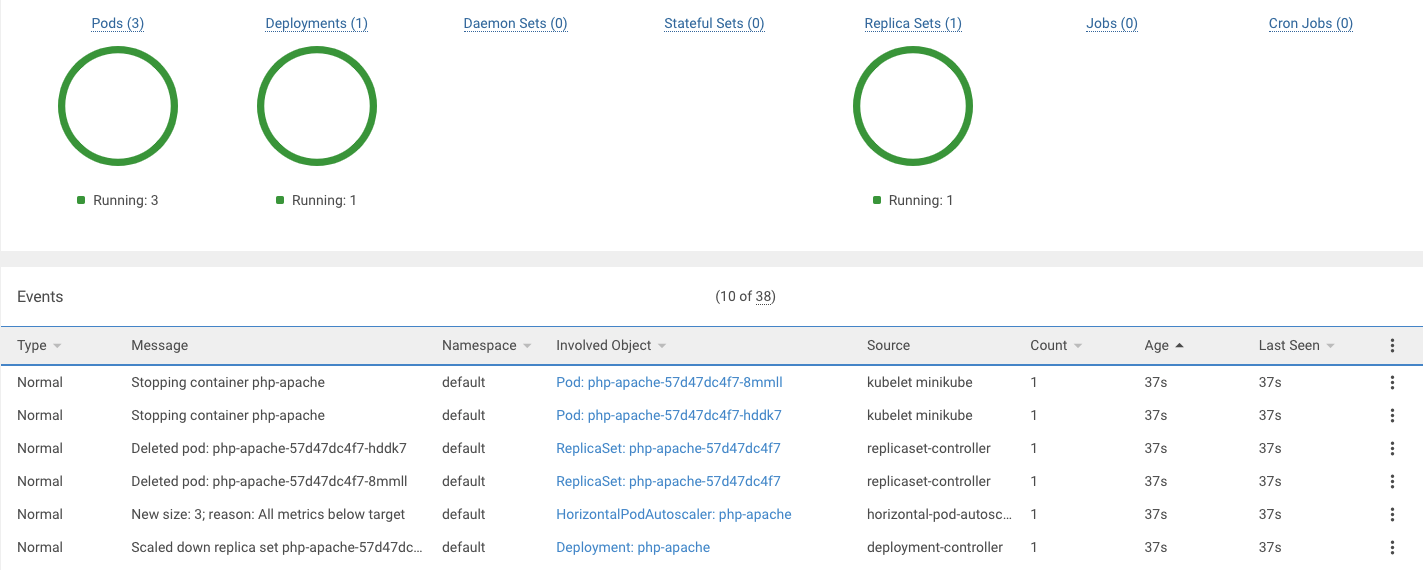
- 根據我們計算出來的副本數,他就會依照計算結果,幫我們自動生成該數量的 Pod,來減緩同一個 Pod 的負載量,接著我們先中斷測試指令,再繼續觀察 HPA :
可以發現因為我們將測試指令中斷後,負載使用量會慢慢降低,但負載降低後,副本數不會馬上變回去,因為怕如果又有大量的使用量會導致 Pod 來不及長出來,所以預設是 5 分鐘 (--horizontal-pod-autoscaler-downscale-stabilization) 才會減至原來的 Pod 數量
Q1 . 出現 x509: cannot validate certificate for 192.168.XXX.XXX because it doesn’t contain any IP SANs 錯誤
Ans 1:是因爲沒有加入 kubelet-insecure-tls=ture 讓 Metrics Server 禁用 TLS 證書驗證,才導致錯誤發生。