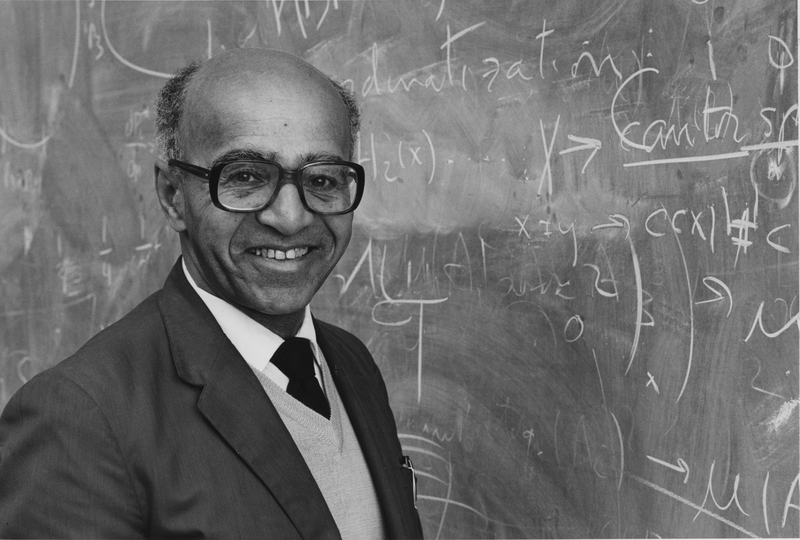
The data this week comes from Wikipedia & Wikipedia. This will be a celebration of Black Lives, their achievements, and many of their battles against racism across their lives. This is in emphasis that Black Lives Matter and we're focusing on a celebration of these lives. Each of those Wikipedia articles above have additional details and sub-links that are highly worth reading through.
For additional datasets related to describing racial problems that still exist in the US, please see a few of our previous #TidyTuesday datasets:
- Note, if you decide to use these datasets please read through the source material to better understand the nuance behind the data.
- School Diversity
- Vera Institute Incarceration Trends
- The Stanford Open Policing Project
The article for this week is the obituary for David Blackwell - Fought racism; became world famous statistician.
There is currently a Petition to rename the Fisher Lectureship after David Blackwell.
The R.A. Fisher Lectureship, established in 1963, is awarded annually to a statistician in recognition of outstanding contributions to aspects of statistics and probability that closely relate to the scientific collection and interpretation of data. Fisher was a prominent proponent of Eugenics and additionally: In 1950, Fisher opposed UNESCO's The Race Question, believing that evidence and everyday experience showed that human groups differ profoundly "in their innate capacity for intellectual and emotional development" and concluded that the "practical international problem is that of learning to share the resources of this planet amicably with persons of materially different nature", and that "this problem is being obscured by entirely well-intentioned efforts to minimize the real differences that exist". The revised statement titled "The Race Concept: Results of an Inquiry" (1951) was accompanied by Fisher's dissenting commentary.
By honoring Fisher we dishonor the entire field of Statistics.
Please consider contributing to this petition.
We'd also like to take the chance to highlight a few potential projects to support or get involved with:
Data for Black Lives is a movement of activists, organizers, and mathematicians committed to the mission of using data science to create concrete and measurable change in the lives of Black people. Since the advent of computing, big data and algorithms have penetrated virtually every aspect of our social and economic lives. These new data systems have tremendous potential to empower communities of color. Tools like statistical modeling, data visualization, and crowd-sourcing, in the right hands, are powerful instruments for fighting bias, building progressive movements, and promoting civic engagement.
But history tells a different story, one in which data is too often wielded as an instrument of oppression, reinforcing inequality and perpetuating injustice. Redlining was a data-driven enterprise that resulted in the systematic exclusion of Black communities from key financial services. More recent trends like predictive policing, risk-based sentencing, and predatory lending are troubling variations on the same theme. Today, discrimination is a high-tech enterprise.
Black Girls CODE is devoted to showing the world that black girls can code, and do so much more. By reaching out to the community through workshops and after school programs, Black Girls CODE introduces computer coding lessons to young girls from underrepresented communities in programming languages such as Scratch or Ruby on Rails. Black Girls CODE has set out to prove to the world that girls of every color have the skills to become the programmers of tomorrow. By promoting classes and programs we hope to grow the number of women of color working in technology and give underprivileged girls a chance to become the masters of their technological worlds. Black Girls CODE's ultimate goal is to provide African-American youth with the skills to occupy some of the 1.4 million computing job openings expected to be available in the U.S. by 2020, and to train 1 million girls by 2040.
Black in AI (BAI) is a multi-institutional, transcontinental initiative designed to create a place for sharing ideas, fostering collaborations, and discussing initiatives to increase the presence of Black individuals in the field of AI. To this end, we hold an annual technical workshop series, run mentoring programs, and maintain various fora for fostering partnerships and collaborations.
If you are in the field of AI and self-identify as Black, please fill out this Google Form to request to join. Note, due to the volume of requests, there may be delays in processing your application.
We also welcome allies to join our group using the Google form. Allies will be added to our email lists, where we send out group updates and requests for assistance.
The firsts.csv dataset has 479 records of African-Americans breaking the color barrier across a wide range of topics. I've adapted the raw text from Wikipedia to highlight:
- The year of the event
- The role/action/topic
- The person or people involved
- Addition of gender
- A category of topics
The science.csv dataset also celebrates the achievements of African-Americans, specifically related to Patents and Scientific achievements. One of the amazing scientists present in this dataset is David Blackwell - an African-American Mathematician and Statistician with significant contributions to game theory, probability theory, information theory, and Bayesian statistics. There is currently a proposal to rename the Fisher Lectureship award after David Blackwell as mentioned above..
# Get the Data
firsts <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-06-09/firsts.csv')
science <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-06-09/science.csv')
# Or read in with tidytuesdayR package (https://github.com/dslc-io/tidytuesdayR)
# Either ISO-8601 date or year/week works!
# Install via pak::pak("dslc-io/tidytuesdayR")
tuesdata <- tidytuesdayR::tt_load('2020-06-09')
tuesdata <- tidytuesdayR::tt_load(2020, week = 24)
firsts <- tuesdata$firsts
| variable | class | description |
|---|---|---|
| year | integer | Year of the achievement |
| accomplishment | character | accomplishment - the actual achievement or attainment |
| person | character | The person or persons who accomplished the specific accomplishment |
| gender | character | Gender - indicates either female AND African-American, or a more general African-American first |
| category | character | A few meta-categories of different accomplishments |
| variable | class | description |
|---|---|---|
| name | character | Name of scientist/inventor |
| birth | integer | Birth year |
| death | integer | Death year (NA if still alive) |
| occupation_s | character | Occupation (1 or more occupation, separated by a ;) |
| inventions_accomplishments | character | Inventions or accomplishment |
| references | character | References to articles |
| links | character | Links to their Wikipedia page (contains images and more information) |
library(tidyverse)
library(rvest)
# URL 1
url_science <- "https://en.wikipedia.org/wiki/List_of_African-American_inventors_and_scientists"
raw_html_sci <- read_html(url_science)
get_source <- function(x){
raw_html_sci %>%
html_nodes("tbody") %>%
.[[2]] %>%
html_nodes(glue::glue("tr:nth-child({x})")) %>%
html_nodes("td:nth-child(1) > a") %>%
html_attr("href")
}
raw_sci_tab <- raw_html_sci %>%
html_table() %>%
.[[2]] %>%
janitor::clean_names() %>%
as_tibble() %>%
mutate(links = map(row_number(), get_source))
clean_sci <- raw_sci_tab %>%
mutate(references = str_replace_all(references, "\\]", ","),
references = str_remove_all(references, "\\[")) %>%
unnest(links) %>%
mutate(links = paste0("https://en.wikipedia.org", links)) %>%
separate(years, into = c("birth", "death"), sep = "–") %>%
mutate(across(c(birth, death), as.integer)) %>%
mutate(occupation_s = str_replace_all(occupation_s, ",", ";"))
clean_sci %>%
filter(str_detect(tolower(occupation_s), "statistician"))
sci_citations <- raw_html_sci %>%
html_node("#mw-content-text > div > div.reflist > div") %>%
html_nodes("li") %>%
html_text() %>%
str_remove("\\^ ") %>%
enframe() %>%
rename(citation_num = name, citation = value) %>%
mutate(citation = str_replace_all(citation, "\"", "'"),
citation = str_remove_all(citation, "\\n"))
sci_citations
clean_sci %>%
add_row(tibble(
name = "Amos, Harold", birth = 1918, death = 2003, occupation_s = "Microbiologist",
inventions_accomplishments = "First African-American department chair at Harvard Medical School",
references = "6,", links = "https://en.wikipedia.org/wiki/Harold_Amos"), .before = 1
) %>%
write_csv(path = "2020/2020-06-09/science.csv")
science <- read_csv("2020/2020-06-09/science.csv")
# Firsts ------------------------------------------------------------------
first_url <- "https://en.wikipedia.org/wiki/List_of_African-American_firsts"
raw_first <- read_html(first_url)
get_year <- function(id_num) {
raw_first %>%
html_nodes(glue::glue("#mw-content-text > div > h4:nth-child({id_num}) > span")) %>%
html_attr("id") %>%
.[!is.na(.)]
}
get_first <- function(id_num){
raw_first %>%
html_nodes(glue::glue("#mw-content-text > div > ul:nth-child({id_num})")) %>%
html_text() %>%
str_split("\n")
}
tidyr::crossing(id_num = 9:389, count = 1:5)
raw_first_df <- tibble(id_num = 9:390) %>%
mutate(year = map(id_num, get_year),
text = map(id_num, get_first))
clean_first <- raw_first_df %>%
mutate(year = as.integer(year)) %>%
fill(year) %>%
unnest(text) %>%
unnest(text) %>%
separate(text, into = c("role", "person"), sep = ": ") %>%
mutate(person = str_remove_all(person, "\\\\"),
person = str_trim(person),
role = str_replace(role, "African American", "African-American")) %>%
select(year, role, person)
clean_first %>%
group_by(year) %>%
summarize(n =n())
first_role <- function(category){
str_detect(tolower(role), category)
}
edu <- paste0(c(
"practice", "graduate", "learning", "college", "university", "medicine",
"earn", "ph.d.", "professor", "teacher", "school", "nobel", "invent", "patent",
"medicine", "degree", "doctor", "medical", "nurse", "physician", "m.d.", "b.a.", "b.s.", "m.b.a",
"principal", "space", "astronaut"
), collapse = "|")
religion <- c("bishop", "rabbi", "minister", "church", "priest", "pastor", "missionary",
"denomination", "jesus", "jesuits", "diocese", "buddhis") %>%
paste0(collapse = "|")
politics <- c(
"diplomat", "elected", "nominee", "supreme court", "legislature", "mayor", "governor",
"vice President", "president", "representatives", "political", "department", "peace prize",
"ambassador", "government", "white house", "postal", "federal", "union", "trade",
"delegate", "alder", "solicitor", "senator", "intelligience", "combat", "commissioner",
"state", "first lady", "cabinet", "advisor", "guard", "coast", "secretary", "senate",
"house", "agency", "staff", "national committee"
) %>%
paste0(collapse = "|")
sports <- c(
"baseball", "football", "basketball", "hockey", "golf", "tennis",
"championship", "boxing", "games", "medal", "game", "sport", "olympic", "nascar",
"coach", "trophy", "nba", "nhl", "nfl", "mlb", "stanley cup", "jockey", "pga",
"race", "driver", "ufc", "champion"
) %>%
paste0(collapse = "|")
military <- c(
"serve", "military", "enlist", "officer", "army", "marine", "naval",
"officer", "captain", "command", "admiral", "prison", "navy", "general",
"force"
) %>%
paste0(collapse = "|")
law <- c("american bar", "lawyer", "police", "judge", "attorney", "law",
"agent", "fbi") %>%
paste0(collapse = "|")
arts <- c(
"opera", "sing", "perform", "music", "billboard", "oscar", "television",
"movie", "network", "tony award", "paint", "author", "book", "academy award", "curator",
"director", "publish", "novel", "grammy", "emmy", "smithsonian",
"conduct", "picture", "pulitzer", "channel", "villain", "cartoon", "tv", "golden globe",
"comic", "magazine", "superhero", "pulitzer", "dancer", "opry", "rock and roll", "radio",
"record") %>%
paste0(collapse = "|")
social <- c("community", "freemasons", "vote", "voting", "rights", "signature",
"royal", "ceo", "community", "movement", "invited", "greek", "million",
"billion", "attendant", "chess", "pilot", "playboy", "own", "daughter",
"coin", "dollar", "stamp", "niagara",
"stock", "north pole", "reporter", "sail around the world", "press", "miss ",
"everest") %>%
paste0(collapse = "|")
first_df <- clean_first %>%
mutate(gender = if_else(str_detect(role, "woman|Woman|her|she|female"),
"Female African American Firsts", "African-American Firsts"),
role = str_remove_all(role, "\""),
person = str_remove_all(person, "\""),
category = case_when(
str_detect(tolower(role), military) ~ "Military",
str_detect(tolower(role), law) ~ "Law",
str_detect(tolower(role), arts) ~ "Arts & Entertainment",
str_detect(tolower(role), social) ~ "Social & Jobs",
str_detect(tolower(role), religion) ~ "Religion",
str_detect(tolower(role), edu) ~ "Education & Science",
str_detect(tolower(role), politics) ~ "Politics",
str_detect(tolower(role), sports) ~ "Sports",
TRUE ~ NA_character_
)) %>%
rename(accomplishment = role)
first_df %>% write_csv(path = "2020/2020-06-09/firsts.csv")
firsts <- read_csv("2020/2020-06-09/firsts.csv")
plot_ex <- first_df %>%
mutate(n = 1) %>%
group_by(category) %>%
mutate(roll_n = cumsum(n)) %>%
ggplot(aes(x = year, y = roll_n, color = category)) +
geom_step(size = 1) +
theme(legend.position = "top") +
tomtom::theme_tomtom() +
scale_y_continuous(breaks = scales::pretty_breaks(n = 6)) +
scale_x_continuous(breaks = seq(1750, 2020, 25)) +
geom_hline(yintercept = 0, size = 1, color = "black") +
labs(x = "", y = "",
title = "Cumulative African-Americans firsts over time",
subtitle = "479 'Firsts' of African-Americans breaking the color barrier across a wide range of topics",
caption = "Data: wikipedia.org/wiki/List_of_African-American_firsts")
ggsave("2020/2020-06-09/pic2.png", plot_ex, height = 8, width = 14, units = "in", dpi = "retina")