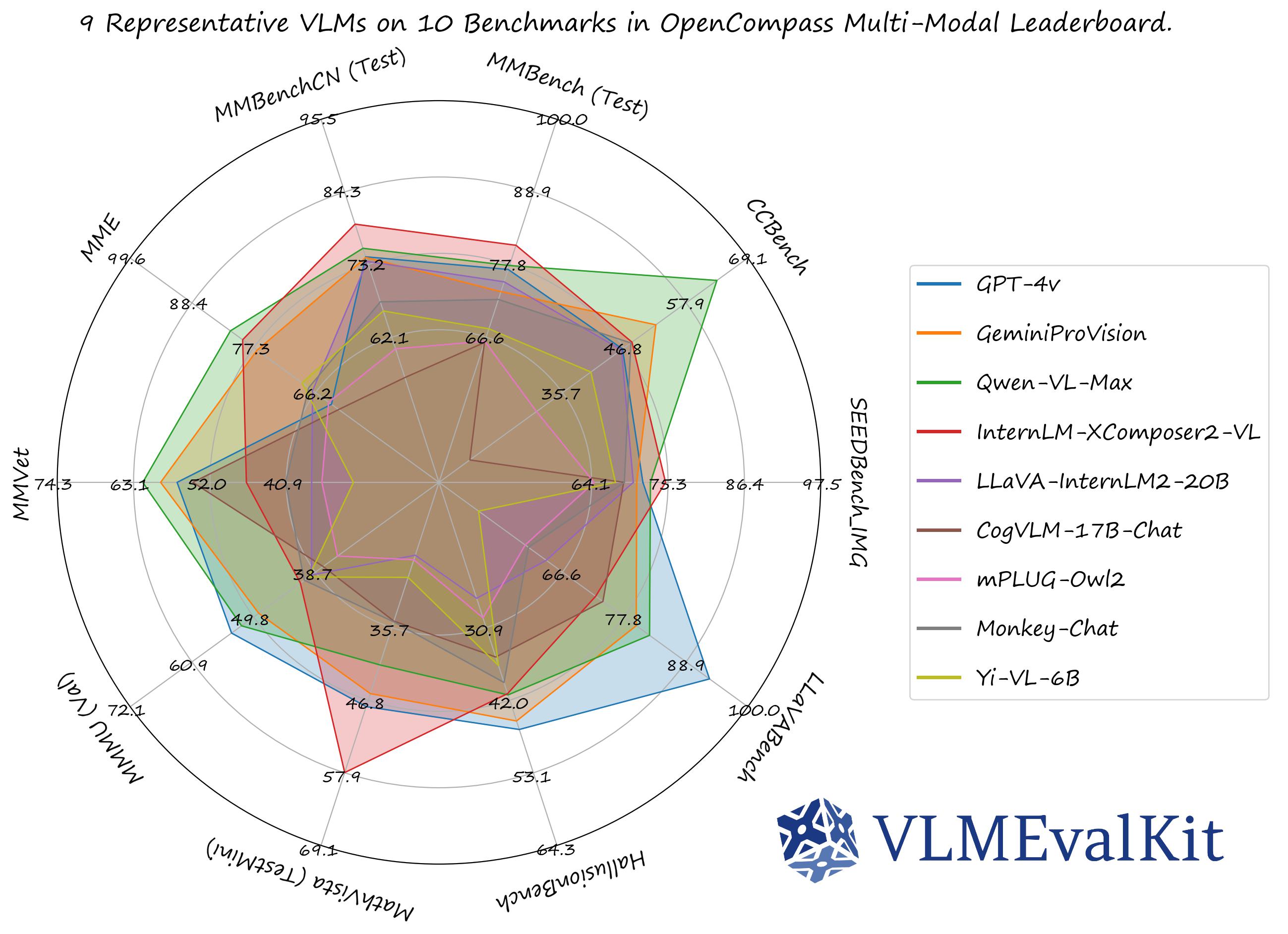
A Toolkit for Evaluating Large Vision-Language Models.





🏆 OC Learderboard • 📊Datasets & Models • 🏗️Quickstart • 🛠️Development • 🎯Goal • 🖊️Citation
🤗 HF Leaderboard • 🤗 Evaluation Records • 🤗 HF Video Leaderboard • 🔊 Discord • 📝 Report
VLMEvalKit (the python package name is vlmeval) is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
- [2024-11-13] Supported MIA-Bench, a multimodal instruction-following benchmark 🔥🔥🔥
- [2024-11-08] Supported Aria, a multimodal native MoE model. And LongVideoBench, a benchmark for long-context interleaved video-language understanding. thanks to teowu 🔥🔥🔥
- [2024-11-04] Supported WorldMedQA-V, the benchmark contains 1000+ Medical VQA problems, in languages of four countries: Brazil, Isarel, Japan, Spanish, as well as their English translations 🔥🔥🔥
- [2024-11-01] Supported an
AUTO_SPLITflag (#566) for evaluation on low-profile GPUs. When set, the model will be automatically split into multiple GPUs (pipeline parallel) to reduce GPU memory usage (currently only support some VLMs: Qwen2-VL, Llama-3.2, LLaVA-OneVision, etc.) 🔥🔥🔥 - [2024-10-30] Supported the evaluation of MLVU and TempCompass. The two benchmarks will be soon incorporated into OpenVLM Video Leaderboard 🔥🔥🔥
- [2024-10-30] Supported Falcon2-VLM 🔥🔥🔥
- [2024-10-30] Supported H2OVL, thanks to smg478. The model is a light-weight VLM features two sizes: 800M and 2B 🔥🔥🔥
- [2024-10-30] Supported LLaVA-Video, thanks to ZhangYuanhan-AI 🔥🔥🔥
- [2024-10-23] Supported Janus-1.3B, a small-scale VLM that is capable of both image generation and understanding, thanks to hills-code 🔥🔥🔥
- [2024-10-22] Supported VIntern, a Vietnamese VLM finetuned on 10M+ Vietnamese QA pairs, thanks to Khang-9966 🔥🔥🔥
The performance numbers on our official multi-modal leaderboards can be downloaded from here!
OpenVLM Leaderboard: Download All DETAILED Results.
Supported Image Understanding Dataset
- By default, all evaluation results are presented in OpenVLM Leaderboard.
- Abbrs:
MCQ: Multi-choice question;Y/N: Yes-or-No Questions;MTT: Benchmark with Multi-turn Conversations;MTI: Benchmark with Multi-Image as Inputs.
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|---|---|---|---|---|---|
|
MMBench Series: MMBench, MMBench-CN, CCBench |
MMBench_DEV_[EN/CN] MMBench_TEST_[EN/CN] MMBench_DEV_[EN/CN]_V11 MMBench_TEST_[EN/CN]_V11 CCBench |
MCQ | MMStar | MMStar | MCQ |
| MME | MME | Y/N | SEEDBench Series | SEEDBench_IMG SEEDBench2 SEEDBench2_Plus |
MCQ |
| MM-Vet | MMVet | VQA | MMMU | MMMU_[DEV_VAL/TEST] | MCQ |
| MathVista | MathVista_MINI | VQA | ScienceQA_IMG | ScienceQA_[VAL/TEST] | MCQ |
| COCO Caption | COCO_VAL | Caption | HallusionBench | HallusionBench | Y/N |
| OCRVQA* | OCRVQA_[TESTCORE/TEST] | VQA | TextVQA* | TextVQA_VAL | VQA |
| ChartQA* | ChartQA_TEST | VQA | AI2D | AI2D_[TEST/TEST_NO_MASK] | MCQ |
| LLaVABench | LLaVABench | VQA | DocVQA+ | DocVQA_[VAL/TEST] | VQA |
| InfoVQA+ | InfoVQA_[VAL/TEST] | VQA | OCRBench | OCRBench | VQA |
| RealWorldQA | RealWorldQA | MCQ | POPE | POPE | Y/N |
| Core-MM- | CORE_MM (MTI) | VQA | MMT-Bench | MMT-Bench_[VAL/ALL] MMT-Bench_[VAL/ALL]_MI |
MCQ (MTI) |
| MLLMGuard - | MLLMGuard_DS | VQA | AesBench+ | AesBench_[VAL/TEST] | MCQ |
| VCR-wiki + | VCR_[EN/ZH]_[EASY/HARD]_[ALL/500/100] | VQA | MMLongBench-Doc+ | MMLongBench_DOC | VQA (MTI) |
| BLINK | BLINK | MCQ (MTI) | MathVision+ | MathVision MathVision_MINI |
VQA |
| MT-VQA | MTVQA_TEST | VQA | MMDU+ | MMDU | VQA (MTT, MTI) |
| Q-Bench1 | Q-Bench1_[VAL/TEST] | MCQ | A-Bench | A-Bench_[VAL/TEST] | MCQ |
| DUDE+ | DUDE | VQA (MTI) | SlideVQA+ | SLIDEVQA SLIDEVQA_MINI |
VQA (MTI) |
| TaskMeAnything ImageQA Random+ | TaskMeAnything_v1_imageqa_random | MCQ | MMMB and Multilingual MMBench+ | MMMB_[ar/cn/en/pt/ru/tr] MMBench_dev_[ar/cn/en/pt/ru/tr] MMMB MTL_MMBench_DEV PS: MMMB & MTL_MMBench_DEV are all-in-one names for 6 langs |
MCQ |
| A-OKVQA+ | A-OKVQA | MCQ | MuirBench+ | MUIRBench | MCQ |
| GMAI-MMBench+ | GMAI-MMBench_VAL | MCQ | TableVQABench+ | TableVQABench | VQA |
| MME-RealWorld+ | MME-RealWorld[-CN] | MCQ | HRBench+ | HRBench[4K/8K] | MCQ |
| MathVerse+ | MathVerse_MINI MathVerse_MINI_Vision_Only MathVerse_MINI_Vision_Dominant MathVerse_MINI_Vision_Intensive MathVerse_MINI_Text_Lite MathVerse_MINI_Text_Dominant |
VQA | AMBER+ | AMBER | Y/N |
| CRPE+ | CRPE_[EXIST/RELATION] | VQA |
MMSearch |
- | - |
| R-Bench+ | R-Bench-[Dis/Ref] | MCQ | WorldMedQA-V+ | WorldMedQA-V | MCQ |
| GQA+ | GQA_TestDev_Balanced | VQA | MIA-Bench+ | MIA-Bench | VQA |
* We only provide a subset of the evaluation results, since some VLMs do not yield reasonable results under the zero-shot setting
+ The evaluation results are not available yet
- Only inference is supported in VLMEvalKit (That includes the TEST splits of some benchmarks that do not include the ground truth answers).
VLMEvalKit will use a judge LLM to extract answer from the output if you set the key, otherwise it uses the exact matching mode (find "Yes", "No", "A", "B", "C"... in the output strings). The exact matching can only be applied to the Yes-or-No tasks and the Multi-choice tasks.
Supported Video Understanding Dataset
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|---|---|---|---|---|---|
| MMBench-Video | MMBench-Video | VQA | Video-MME | Video-MME | MCQ |
| MVBench | MVBench/MVBench_MP4 | MCQ | MLVU | MLVU | MCQ & VQA |
| TempCompass | TempCompass | MCQ & Y/N & Caption | LongVideoBench | LongVideoBench | MCQ |
Supported API Models
| GPT-4v (20231106, 20240409) 🎞️🚅 | GPT-4o 🎞️🚅 | Gemini-1.0-Pro 🎞️🚅 | Gemini-1.5-Pro 🎞️🚅 | Step-1V 🎞️🚅 |
|---|---|---|---|---|
| Reka-[Edge / Flash / Core]🚅 | Qwen-VL-[Plus / Max] 🎞️🚅 Qwen-VL-[Plus / Max]-0809 🎞️🚅 |
Claude3-[Haiku / Sonnet / Opus] 🎞️🚅 | GLM-4v 🚅 | CongRong 🎞️🚅 |
| Claude3.5-Sonnet (20240620, 20241022) 🎞️🚅 | GPT-4o-Mini 🎞️🚅 | Yi-Vision🎞️🚅 | Hunyuan-Vision🎞️🚅 | BlueLM-V 🎞️🚅 |
Supported PyTorch / HF Models
🎞️: Support multiple images as inputs.
🚅: Models can be used without any additional configuration/operation.
🎬: Support Video as inputs.
Transformers Version Recommendation:
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
- Please use
transformers==4.33.0for:Qwen series,Monkey series,InternLM-XComposer Series,mPLUG-Owl2,OpenFlamingo v2,IDEFICS series,VisualGLM,MMAlaya,ShareCaptioner,MiniGPT-4 series,InstructBLIP series,PandaGPT,VXVERSE. - Please use
transformers==4.36.2for:Moondream1. - Please use
transformers==4.37.0for:LLaVA series,ShareGPT4V series,TransCore-M,LLaVA (XTuner),CogVLM Series,EMU2 Series,Yi-VL Series,MiniCPM-[V1/V2],OmniLMM-12B,DeepSeek-VL series,InternVL series,Cambrian Series,VILA Series,Llama-3-MixSenseV1_1,Parrot-7B,PLLaVA Series. - Please use
transformers==4.40.0for:IDEFICS2,Bunny-Llama3,MiniCPM-Llama3-V2.5,360VL-70B,Phi-3-Vision,WeMM. - Please use
transformers==4.44.0for:Moondream2,H2OVL series. - Please use
transformers==4.45.0for:Aria. - Please use
transformers==latestfor:LLaVA-Next series,PaliGemma-3B,Chameleon series,Video-LLaVA-7B-HF,Ovis series,Mantis series,MiniCPM-V2.6,OmChat-v2.0-13B-sinlge-beta,Idefics-3,GLM-4v-9B,VideoChat2-HD,RBDash_72b,Llama-3.2 series,Kosmos series.
Torchvision Version Recommendation:
Note that some VLMs may not be able to run under certain torchvision versions, we recommend the following settings to evaluate each VLM:
- Please use
torchvision>=0.16for:Moondream seriesandAria
Flash-attn Version Recommendation:
Note that some VLMs may not be able to run under certain flash-attention versions, we recommend the following settings to evaluate each VLM:
- Please use
pip install flash-attn --no-build-isolationfor:Aria
# Demo
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# Forward Single Image
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
print(ret) # The image features a red apple with a leaf on it.
# Forward Multiple Images
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
print(ret) # There are two apples in the provided images.See [QuickStart | 快速开始] for a quick start guide.
To develop custom benchmarks, VLMs, or simply contribute other codes to VLMEvalKit, please refer to [Development_Guide | 开发指南].
Call for contributions
To promote the contribution from the community and share the corresponding credit (in the next report update):
- All Contributions will be acknowledged in the report.
- Contributors with 3 or more major contributions (implementing an MLLM, benchmark, or major feature) can join the author list of VLMEvalKit Technical Report on ArXiv. Eligible contributors can create an issue or dm kennyutc in VLMEvalKit Discord Channel.
Here is a contributor list we curated based on the records.
The codebase is designed to:
- Provide an easy-to-use, opensource evaluation toolkit to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results easy to reproduce.
- Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to implement a single
generate_inner()function, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
The codebase is not designed to:
- Reproduce the exact accuracy number reported in the original papers of all 3rd party benchmarks. The reason can be two-fold:
- VLMEvalKit uses generation-based evaluation for all VLMs (and optionally with LLM-based answer extraction). Meanwhile, some benchmarks may use different approaches (SEEDBench uses PPL-based evaluation, eg.). For those benchmarks, we compare both scores in the corresponding result. We encourage developers to support other evaluation paradigms in the codebase.
- By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, some VLMs may have their specific prompt templates (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
If you find this work helpful, please consider to star🌟 this repo. Thanks for your support!
If you use VLMEvalKit in your research or wish to refer to published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
@misc{duan2024vlmevalkit,
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
year={2024},
eprint={2407.11691},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.11691},
}