Releases: huggingface/trl
v0.7.9: Patch release for DPO & SFTTrainer
v0.7.9: Patch release for DPO & SFTTrainer
This is a patch release that fixes critical issues with SFTTrainer & DPOTrainer, together with minor fixes for PPOTrainer and DataCollatorForCompletionOnlyLM
What's Changed
- Release: v0.7.8 by @younesbelkada in #1200
- set dev version by @younesbelkada in #1201
- Fix instruction token masking by @mgerstgrasser in #1185
- Fix reported KL in PPO trainer by @mgerstgrasser in #1180
- [
DPOTrainer] Fix peft + DPO + bf16 if one usesgenerate_during_evalor pre-computed logits by @younesbelkada in #1203 - Revert "Address issue #1122" by @younesbelkada in #1205
- Release: v0.7.9 by @younesbelkada in #1206
Full Changelog: v0.7.8...v0.7.9
Contributors
Assets 2
v0.7.8: Unsloth tag, DPO fixes, PEFT support for DDPO
v0.7.8: Unsloth tag, DPO fixes, PEFT support for DDPO
Unsloth tag for xxxTrainer
If users use Unsloth library, the unsloth tag gets automatically pushed on the Hub.
- [
xxxTrainer] Add unsloth tag by @younesbelkada in #1130
DPO fixes
Some important fixes for DPO has been introduced to address: https://twitter.com/jon_durbin/status/1743575483365699809 and to make DPO faster
- Allow separate devices for target/ref models. by @jondurbin in #1190
- Allow swapping PEFT adapters for target/ref model. by @jondurbin in #1193
- Change device access order for speedup of calculating metrics in DPOTrainer by @brcps12 in #1154
DDPO + PEFT
Now DDPO supports PEFT
- add: support for
peftin ddpo. by @sayakpaul in #1165
Other fixes
- add peft_module_casting_to_bf16 in DPOTrainer by @sywangyi in #1143
- SFT Tokenizer Fix by @ChrisCates in #1142
- Minor fixes to some comments in some examples. by @mattholl in #1156
- Correct shapes in docstring of PPOTrainer's train_minibatch method by @nikihowe in #1170
- Update sft_trainer.py by @Hemanthkumar2112 in #1162
- Fix batch all gather by @vwxyzjn in #1177
- Address issue #1122 by @maneandrea in #1174
- Fix misleading variable "epoch" from the training loop from PPOTrainer Doc. by @Jfhseh in #1171
- SFTTrainer: follow args.remove_unused_columns by @mgerstgrasser in #1188
- Handle last token from generation prompt by @pablovicente in #1153
New Contributors
- @ChrisCates made their first contribution in #1142
- @brcps12 made their first contribution in #1154
- @mattholl made their first contribution in #1156
- @sayakpaul made their first contribution in #1165
- @nikihowe made their first contribution in #1170
- @Hemanthkumar2112 made their first contribution in #1162
- @maneandrea made their first contribution in #1174
- @Jfhseh made their first contribution in #1171
- @mgerstgrasser made their first contribution in #1188
- @pablovicente made their first contribution in #1153
- @jondurbin made their first contribution in #1190
Full Changelog: v0.7.7...v0.7.8
Contributors
Assets 2
v0.7.7
v0.7.7: Patch release PPO & DDPO tags
A fix has been introduce to fix a breaking change with PPOTrainer.push_to_hub() and DDPOTrainer.push_to_hub()
- [
PPOTrainer/DDPOTrainer] Fix ppo & ddpo push to Hub by @younesbelkada in #1141
What's Changed
- Release: v0.7.6 by @younesbelkada in #1134
- set dev version by @younesbelkada in #1135
- clear up the parameters of supervised_finetuning.py by @sywangyi in #1126
- Add type hints to core.py by @zachschillaci27 in #1097
- fix_ddpo_demo by @zhangsibo1129 in #1129
- Add npu support for ppo example by @zhangsibo1129 in #1128
New Contributors
- @zachschillaci27 made their first contribution in #1097
- @zhangsibo1129 made their first contribution in #1129
Full Changelog: v0.7.6...v0.7.7
Contributors
Assets 2
v0.7.6: Patch release - Multi-tag instead of single tags for `xxxTrainer`
Patch release: Multi-tag instead of single tags for xxxTrainer
This is a patch release to push multiple tags (e.g. trl & sft) instead of one tag
What's Changed
- Release: v0.7.5 by @younesbelkada in #1131
- set dev version by @younesbelkada in #1132
- [
xxxTrainer] multi-tags support for tagging by @younesbelkada in #1133
Full Changelog: v0.7.5...v0.7.6
Contributors
Assets 2
v0.7.5: IPO & KTO & cDPO loss, `DPOTrainer` enhancements, automatic tags for `xxxTrainer`
IPO & KTO & cDPO loss, DPOTrainer enhancements, automatic tags for xxxTrainer
Important enhancements for DPOTrainer
This release introduces many new features in TRL for DPOTrainer:
- IPO-loss for a better generalization of DPO algorithm
- KTO & cDPO loss
- You can also pass pre-computed logits to
DPOTrainer
- [DPO] Refactor eval logging of dpo trainer by @mnoukhov in #954
- Fixes reward and text gathering in distributed training by @edbeeching in #850
- remove spurious optimize_cuda_cache deprecation warning on init by @ChanderG in #1045
- Revert "[DPO] Refactor eval logging of dpo trainer (#954)" by @lvwerra in #1047
- Fix DPOTrainer + PEFT 2 by @rdk31 in #1049
- [DPO] IPO Training loss by @kashif in #1022
- [DPO] cDPO loss by @kashif in #1035
- [DPO] use ref model logprobs if it exists in the data by @kashif in #885
- [DP0] save eval_dataset for subsequent calls by @kashif in #1125
- [DPO] rename kto loss by @kashif in #1127
- [DPO] add KTO loss by @kashif in #1075
Automatic xxxTrainer tagging on the Hub
Now, trainers from TRL pushes automatically tags trl-sft, trl-dpo, trl-ddpo when pushing models on the Hub
- [
xxxTrainer] Add tags to all trainers in TRL by @younesbelkada in #1120
unsloth 🤝 TRL
We encourage users to try out unsloth library for faster LLM fine-tuning using PEFT & TRL's SFTTrainer and DPOTrainer
- [
Docs] Add unsloth optimizations in TRL's documentation by @younesbelkada in #1119
What's Changed
- set dev version by @younesbelkada in #970
- [
Tests] Add non optional packages tests by @younesbelkada in #974 - [DOCS] Fix outdated references to
examples/by @alvarobartt in #977 - Update README.md by @GeekDream-x in #994
- [DataCollatorForCompletionOnlyLM] Warn on identical
eos_token_idandpad_token_idby @MustSave in #988 - [
DataCollatorForCompletionOnlyLM] Add more clarification / guidance in the casetokenizer.pad_token_id == tokenizer.eos_token_idby @younesbelkada in #992 - make distributed true for multiple process by @allanj in #997
- Fixed wrong trigger for warning by @zabealbe in #971
- Update how_to_train.md by @halfrot in #1003
- Adds
requires_gradto input for non-quantized peft models by @younesbelkada in #1006 - [Multi-Adapter PPO] Fix and Refactor reward model adapter by @mnoukhov in #982
- Remove duplicate data loading in rl_training.py by @viethoangtranduong in #1020
- [Document] Minor fixes of sft_trainer document by @mutichung in #1029
- Update utils.py by @ZihanWang314 in #1012
- spelling is hard by @grahamannett in #1043
- Fixing accelerator version function call. by @ParthaEth in #1056
- [SFT Trainer] precompute packed iterable into a dataset by @lvwerra in #979
- Update doc CI by @lewtun in #1060
- Improve PreTrainedModelWrapper._get_current_device by @billvsme in #1048
- Update doc for the computer_metrics argument of SFTTrainer by @albertauyeung in #1062
- [
core] Fix failing tests on main by @younesbelkada in #1065 - [
SFTTrainer] Fix Trainer when args is None by @younesbelkada in #1064 - enable multiple eval datasets by @peter-sk in #1052
- Add missing
loss_typeinValueErrormessage by @alvarobartt in #1067 - Add args to SFT example by @lewtun in #1079
- add local folder support as input for rl_training. by @sywangyi in #1078
- Make CI happy by @younesbelkada in #1080
- Removing
tyroinsft_llama2.pyby @vwxyzjn in #1081 - Log arg consistency by @tcapelle in #1084
- Updated documentation for docs/source/reward_trainer.mdx to import th… by @cm2435 in #1092
- [Feature] Add Ascend NPU accelerator support by @statelesshz in #1096
peft_module_casting_to_bf16util method,append_concat_tokenflag, remove callbackPeftSavingCallbackby @pacman100 in #1110- Make prepending of bos token configurable. by @pacman100 in #1114
- fix gradient checkpointing when using PEFT by @pacman100 in #1118
- Update
descriptioninsetup.pyby @alvarobartt in #1101
New Contributors
- @alvarobartt made their first contribution in #977
- @GeekDream-x made their first contribution in #994
- @MustSave made their first contribution in #988
- @allanj made their first contribution in #997
- @zabealbe made their first contribution in #971
- @viethoangtranduong made their first contribution in #1020
- @mutichung made their first contribution in #1029
- @ZihanWang314 made their first contribution in #1012
- @grahamannett made their first contribution in #1043
- @ChanderG made their first contribution in #1045
- @rdk31 made their first contribution in #1049
- @ParthaEth made their first contribution in #1056
- @billvsme made their first contribution in #1048
- @albertauyeung made their first contribution in #1062
- @peter-sk made their first contribution in #1052
- @sywangyi made their first contribution in #1078
- @tcapelle made their first contribution in #1084
- @cm2435 made their first contribution in #1092
- @statelesshz made their first contribution in #1096
- @pacman100 made their first contribution in #1110
Full Changelog: v0.7.4...v0.7.5
Contributors
Assets 2
v0.7.4: Patch Release
Patch Release
This release is a patch release that addresses an issue for users that have TRL installed without PEFT
What's Changed
- Release: v0.7.3 by @younesbelkada in #965
- set dev version by @younesbelkada in #966
- [
core] Fix peft config typehint by @younesbelkada in #967 - Pin bnb to <=0.41.1 by @younesbelkada in #968
Full Changelog: v0.7.3...v0.7.4
Contributors
Assets 2
v0.7.3:`IterativeTrainer`, NEFTune and major bugfixes for `DPOTrainer` and Distributed Training
IterativeTrainer, NEFTune and major bugfixes for DPOTrainer and Distributed Training
In this release we introduce two new features, IterativeTrainer from @gaetanlop and NEFTune, together with important bugfixes for distributed training.
IterativeTrainer
Iterative fine-tuning is a training method that enables to perform custom actions (generation and filtering for example) between optimization steps. In TRL we provide an easy-to-use API to fine-tune your models in an iterative way in just a few lines of code.
Read more about it here: https://huggingface.co/docs/trl/iterative_sft_trainer
- Introducing the Iterative Trainer by @gaetanlop in #737
NEFTune
NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
- [
SFTTrainer] Adds NEFTune intoSFTTrainerby @younesbelkada in #871 - [
NEFTune] Make use of forward hooks instead by @younesbelkada in #889 - Generalize NEFTune for FSDP, DDP, ... by @younesbelkada in #924
- [
NEFTune] Make use of forward hooks instead by @younesbelkada in #889
Read more about it here
Major bugfixes
Major bugfixes have been addressed to tackle many issues with distributed training and gradient checkpointing.
- [
DPO] fix DPO + GC issues by @younesbelkada in #927 - [
core/DDP] Fix RM trainer + DDP + quantization + propagategradient_checkpointing_kwargsin SFT & DPO by @younesbelkada in #912
DPOTrainer enhancements and fixes
The DPOTrainer now comes with multiple enhancements and bugfixes! Check them out below
- [DPO] add SLiC hinge loss to DPOTrainer by @kashif in #866
- Fix DPOTrainer + PEFT by @younesbelkada in #941
- [DPO] Merge initial peft model if trainer has a peft_config by @kashif in #956
- Adds model kwargs to SFT and DPO trainers by @edbeeching in #951
- fix: dpo trainer ds config by @mengban in #957
- hotfix for dpo trainer by @mnoukhov in #919
- Fix dpo_llama2.py by @younesbelkada in #934
What's Changed
- Release: v0.7.2 by @younesbelkada in #863
- set dev version by @younesbelkada in #864
- Remove duplicate key in
reward_modeling.pyby @vwxyzjn in #890 - fix peft_config type by @u2takey in #883
- fix: remove useless token by @rtrompier in #896
- [reward_modeling] Cleaning example script by @gaetanlop in #882
- Fix couple wrong links on lib homepage by @paulbricman in #908
- Add whiten ops before compute advatanges by @SingL3 in #887
- Fix broken link/markdown by @osanseviero in #903
- [Update reward_trainer.py] append PeftSavingCallback if callbacks is not None by @zuoxingdong in #910
- deactivate MacOS CI by @lvwerra in #913
- fix stackllama2 sft gradient checkpointing by @nrailg in #906
- updating PPOTrainer docstring by @lomahony in #897
- Bump minimum
tyroversion by @brentyi in #928 - [Feature] Enable Intel XPU support by @abhilash1910 in #839
- [
SFTTrainer] Make sure to not conflict betweentransformersand TRL implementation by @younesbelkada in #933 - Fix stale bot by @younesbelkada in #935
- Optionally logging reference response by @vwxyzjn in #847
- [
CI] Fix CI with new transformers release by @younesbelkada in #946 - Fix unwrapping peft models by @kkteru in #948
- Added support for custom EncoderDecoder models by @ribesstefano in #911
New Contributors
- @u2takey made their first contribution in #883
- @rtrompier made their first contribution in #896
- @paulbricman made their first contribution in #908
- @SingL3 made their first contribution in #887
- @nrailg made their first contribution in #906
- @lomahony made their first contribution in #897
- @brentyi made their first contribution in #928
- @abhilash1910 made their first contribution in #839
- @kkteru made their first contribution in #948
- @ribesstefano made their first contribution in #911
- @mengban made their first contribution in #957
Full Changelog: v0.7.2...v0.7.3
Contributors
Assets 2
v0.7.2
0.7.2: Flash Attention documentation and Minor bugfixes
In this release we provide minor bugfixes and smoother user experience for all public classes. We also added some clarification on the documentation on how to use Flash Attention with SFTTrainer
How to use Flash Attention with SFTTrainer:
- Update sft_trainer.mdx to highlight Flash Attention features by @younesbelkada in #807
What's Changed
- Release: v0.7.1 by @younesbelkada in #709
- set dev version by @younesbelkada in #710
- fix device issue by @backpropper in #681
- Update docs on gms8k by @vwxyzjn in #711
- [
Docs] Fix sft mistakes by @younesbelkada in #717 - Fix: RuntimeError: 'weight' must be 2-D issue by @jp1924 in #687
- Add pyproject.toml by @mnoukhov in #690
- [
core] Bump peft to 0.4.0 by @younesbelkada in #720 - Refactor RewardTrainer hyperparameters into dedicated dataclass by @lewtun in #726
- Fix DeepSpeed ZeRO-3 in PPOTrainer by @lewtun in #730
- [
SFTTrainer] Check correctly for condition by @younesbelkada in #668 - Add epsilon to score normalization by @zfang in #727
- Enable gradient checkpointing to be disabled for reward modelling by @lewtun in #725
- [DPO] fixed metrics typo by @kashif in #743
- Seq2Seq model support for DPO by @gaetanlop in #586
- [DPO] fix ref_model by @i4never in #745
- [
core] Fix import ofrandn_tensorby @younesbelkada in #751 - Add benchmark CI by @vwxyzjn in #752
- update to
prepare_model_for_kbit_trainingby @mnoukhov in #728 - benchmark CI fix by @vwxyzjn in #755
- EOS token processing for multi-turn DPO by @natolambert in #741
- Extend DeepSpeed integration to ZeRO-{1,2,3} by @lewtun in #758
- Imrpove benchmark ci by @vwxyzjn in #760
- [PPOTrainer] - add comment of zero masking (from second query token) by @zuoxingdong in #763
- Refactor and benchmark by @vwxyzjn in #662
- Benchmark CI (actual) by @vwxyzjn in #754
- docs: add initial version of docs for
PPOTrainerby @davidberenstein1957 in #665 - Support fork in benchmark CI by @vwxyzjn in #764
- Update benchmark.yml by @vwxyzjn in #773
- Benchmark CI fix by @vwxyzjn in #775
- Benchmark CI fix by @vwxyzjn in #776
- Update benchmark.yml by @vwxyzjn in #777
- Update benchmark.yml by @vwxyzjn in #778
- Update benchmark.yml by @vwxyzjn in #779
- Update benchmark.yml by @vwxyzjn in #780
- Update benchmark.yml by @vwxyzjn in #781
- Update benchmark.yml by @vwxyzjn in #782
- Ensure
RewardConfigis backwards compatible by @lewtun in #748 - Temp benchmark ci dir by @vwxyzjn in #765
- Changed the default value of the
log_withargument by @filippobistaffa in #792 - Add default Optim to DPO example by @natolambert in #759
- Add margin to RM training by @jvhoffbauer in #719
- [
DPO] Revert "Add default Optim to DPO example (#759)" by @younesbelkada in #799 - Add deepspeed experiment by @vwxyzjn in #795
- [
Docs] Clarify PEFT docs by @younesbelkada in #797 - Fix docs bug on sft_trainer.mdx by @younesbelkada in #808
- [
PPOTrainer] Fixes ppo trainer generate nit by @younesbelkada in #798 - Allow passing the token_ids as instruction_template in DataCollatorForCompletionOnlyLM by @devxpy in #749
- init custom eval loop for further DPO evals by @natolambert in #766
- Add RMSProp back to DPO by @natolambert in #821
- [DPO] add option for compute_metrics in DPOTrainer by @kashif in #822
- Small fixes to the PPO trainer doc and script. by @namin in #811
- Unify sentiment documentation by @vwxyzjn in #803
- Fix DeepSpeed ZeRO-{1,2} for DPOTrainer by @lewtun in #825
- Set trust remote code to false by default by @lewtun in #833
- [MINOR:TYPOS] Update README.md by @cakiki in #829
- Clarify docstrings, help messages, assert messages in merge_peft_adapter.py by @larekrow in #838
- add DDPO to index by @lvwerra in #826
- Raise error in
create_reference_model()when ZeRO-3 is enabled by @lewtun in #840 - Use uniform config by @vwxyzjn in #817
- Give
lewtunpower by @lvwerra in #856 - Standardise example scripts by @lewtun in #842
- Fix version check in import_utils.py by @adampauls in #853
- dont use get_peft_model if model is already peft by @abhishekkrthakur in #857
- [
core] Fix import issues by @younesbelkada in #859 - Support both old and new diffusers import path by @osanseviero in #843
New Contributors
- @backpropper made their first contribution in #681
- @jp1924 made their first contribution in #687
- @i4never made their first contribution in #745
- @zuoxingdong made their first contribution in #763
- @davidberenstein1957 made their first contribution in #665
- @filippobistaffa made their first contribution in #792
- @devxpy made their first contribution in #749
- @namin made their first contribution in #811
- @cakiki made their first contribution in #829
- @larekrow made their first contribution in #838
- @adampauls made their first contribution in #853
- @abhishekkrthakur made their first contribution in #857
- @osanseviero made their first contribution in #843
Full Changelog: v0.7.1...v0.7.2
Contributors
Assets 2
v0.7.1: Patch release
Patch release: fix bug with PPOTrainer and log_stats
Fixed a bug with log_stats of PPOTrainer to avoid breaking behaviour
- [
PPOTrainer] A workaround for failing log_stats by @younesbelkada in #708
What's Changed
- Release: v0.7.0 by @younesbelkada in #706
- set dev version by @younesbelkada in #707
Full Changelog: v0.7.0...v0.7.1
Contributors
Assets 2
v0.7.0: Text Environments, Agents & Tools
Text environments, LLMs with tools and agents!
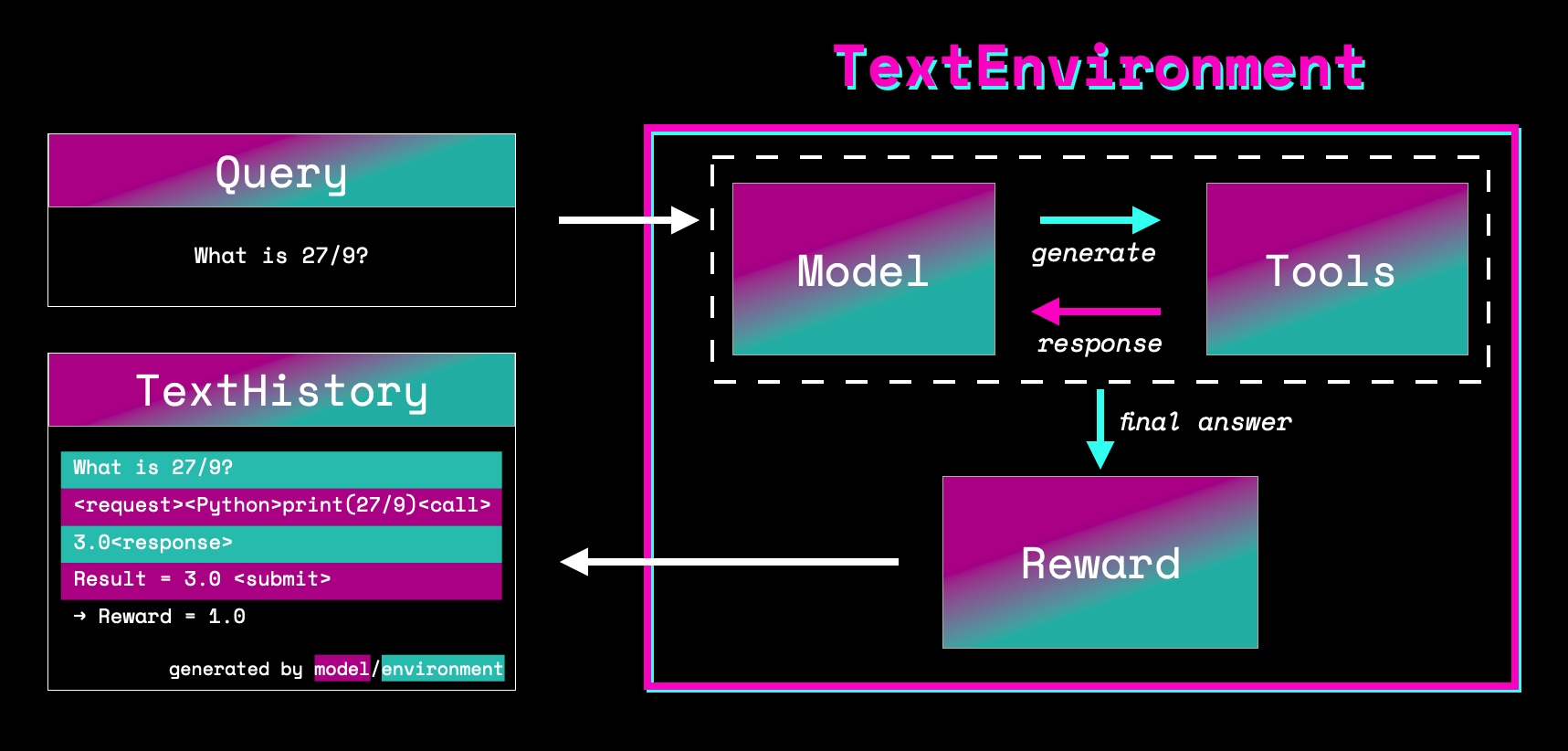
Text environments provide a learning ground for language agents. It allows a language model to use tools to accomplish a task such as using a Python interpreter to answer math questions or using a search index for trivia questions. Having access to tools allows language models to solve tasks that would be very hard for the models itself but can be trivial for the appropriate tools.
We are excited to bring to the community a complete set of functionalities and full examples to train LLMs to use tools!
Check out the documentation page here and few examples below:
- fine tune a LLM to learn to use a simple calculator tool
- fine tune a LLM to learn to use a Question Answering tool to answer general knowledge questions
- fine tune a LLM to learn to use a Python interpreter
What's Changed
- Release: v0.6.0 by @younesbelkada in #684
- set dev version by @younesbelkada in #685
- [DPO] fix DPO ref_model=None by @kashif in #703
- [Docs] fix example README.md by @kashif in #705
- TextEnvironments by @lvwerra in #424
Full Changelog: v0.6.0...v0.7.0