#Installation of the HTML Generating tools and Web Site This page explains setup of combined build and web app. If you are only installing one or the other you may skip some steps.
- Go
- Docker
- About 10 GB of memory for the build server, much less for only the web app
- GCS bucket optional for cloud hosting
- Attached block storage device for cloud hosting
These instructions assume that you will work directly under $HOME. Change the top level directory if you are working in another location.
Get the source from GitHub
git clone git://github.com/alexamies/buddhist-dictionary
git clone git://github.com/alexamies/chinesenotes.comCheck whether you have nodejs installed
node -v
If needed install nodejs.
cd web-resources
To install the MD Web components and dependencies:
npm install
npm install --save-dev babel-core babel-loader babel-preset-es2015
To compile the JavaScript source run
npm run build
# Install Go lang
cd buddhist-dictionary
bin/ntireader.sh
First time setup:
export BUCKET={your bucket}
gsutil mb gs://$BUCKET
gsutil web set -m index.html -e 404.html gs://$BUCKET
When generating new content
bin/push.sh
The JSON file containing the version of the dictionary for the web client should be cached to reduce download time and cost. Create a bucket for it.
export CBUCKET={your bucket}
WEB_DIR=web-staging
# First time
gsutil mb gs://${CBUCKET}
gsutil iam ch allUsers:objectViewer gs://${CBUCKET}
# After updating the dictionary
gsutil -m -h "Cache-Control:public,max-age=3600" \
-h "Content-Type:application/json" \
-h "Content-Encoding:gzip" \
cp -a public-read -r $WEB_DIR/dist/ntireader.json.gz \
gs://${CBUCKET}/cached/ntireader.json.gz
Test that content is returned properly:
curl -I http://ntireader.org/cached/ntireader.json.gzThe application uses a Mariadb database.
To start a Docker container with Mariadb and connect to it from a MySQL command
line client execute the command below. First, set environment variable
MYSQL_ROOT_PASSWORD.
docker run --name mariadb -p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=$MYSQL_ROOT_PASSWORD -d \
--mount type=bind,source="$(pwd)"/data,target=/ntidata \
mariadb:10.3
docker exec -it mariadb bash
mysql --local-infile=1 -h localhost -u root -p
The data in the database is persistent unless the container is deleted. To restart the database use the command
docker restart mariadb
To load data from other sources connect to the database container
Copy the text files to an object store. If you prefer not to use GCS, then you can use the local file system on the application server. The instructions here are for GCS. See Authenticating to Cloud Platform with Service Accounts for detailed instructions on authentication.
TEXT_BUCKET={your txt bucket}
# First time
gsutil mb gs://$TEXT_BUCKET
gsutil -m rsync -d -r corpus gs://$TEXT_BUCKET
To enable the web application to access the storage system, create a service account with a GCS Storage Object Admin role and download the JSOn credentials file, as described in Create service account credentials. Assuming that you saved the file in the current working directory as credentials.json, create a local environment variable for local testing
export GOOGLE_APPLICATION_CREDENTIALS=$PWD/credentials.json
go get -u cloud.google.com/go/storage
If running on Debian, add the current user to the sudo group
sudo groupadd docker
newgrp dockerBuild the Docker image
docker build -f Dockerfile -t nti-image .Run it locally with minimal features (C-E dictionary lookp only) enabled
docker run -it --rm -p 8080:8080 --name nti-app nti-image
Test basic lookup with curl
curl http://localhost:8080/find/?query=你好
Push to Google Container Registry
docker tag nti-image gcr.io/$PROJECT/nti-image:$TAG
docker -- push gcr.io/$PROJECT/nti-image:$TAG
Or use Cloud Build
BUILD_ID=[your build id]
gcloud builds submit --config cloudbuild.yaml . \
--substitutions=_IMAGE_TAG="$BUILD_ID"Check that the expected image has been added with the command
IMAGE_FAMILY=nti-image
gcloud container images list-tags gcr.io/${PROJECT_ID}/${IMAGE_FAMILY}New: Replacing management of the Mariadb database in a Kubernetes cluster Follow instructions in Cloud SQL Quickstart using the Cloud Console.
Connect to the instance from the Cloud Shell of a GCE instance
DB_INSTANCE=[your database instance]
gcloud sql connect $DB_INSTANCE --user=root
Execute statements in first_time_setup.sql, data/dictionary/dictionary.ddl, and data/corpus/corpus_index.ddl to define the database and tables as per instructions at
https://github.com/alexamies/chinesenotes-go
Don't forget to select the proper database
USE ntireader;Load the proper files into the words table as per data/load_data.sql, the proper corpus files into the database as per data/load_index.sql, and the proper index files as per index/load_word_freq.sql.
Deploy the web app to Cloud Run
PROJECT_ID=[Your project]
IMAGE=gcr.io/${PROJECT_ID}/cn-app-image:${BUILD_ID}
IMAGE=gcr.io/${PROJECT_ID}/nti-image:${BUILD_ID}
SERVICE=ntireader
REGION=us-central1
MEMORY=800Mi
TEXT_BUCKET=[Your GCS bucket name for text files]
gcloud run deploy --platform=managed $SERVICE \
--image $IMAGE \
--region=$REGION \
--memory "$MEMORY" \
--allow-unauthenticated \
--set-env-vars TEXT_BUCKET="$TEXT_BUCKET" \
--set-env-vars CNREADER_HOME="/" \
--set-env-vars PROJECT_ID=${PROJECT_ID} \
--set-env-vars AVG_DOC_LEN="6376"If needing to update traffic to the latest version run
gcloud run services update-traffic --platform=managed $SERVICE \
--to-latest \
--region=$REGION
Test it with the command
curl $URL/find/?query=你好You should see a JSON reply.
Configure a load balancer that will direct HTTP requests to the backend bucket and Cloud Run service based on path.
[Deprecated] Use these commands, setting the values for INSTANCE_GROUP and HOST appropriately for your installation:
HOST=[Your value]
gcloud compute firewall-rules create ntireader-app-rule \
--allow tcp:$PORT \
--source-ranges 130.211.0.0/22,35.191.0.0/16
gcloud compute health-checks create http ntireader-app-check --port=$PORT \
--request-path=/healthcheck/
BACKEND_NAME=ntireader-service-prod
gcloud compute backend-services create $BACKEND_NAME \
--protocol HTTP \
--health-checks ntireader-app-check \
--global
gcloud compute backend-services add-backend $BACKEND_NAME \
--balancing-mode UTILIZATION \
--max-utilization 0.8 \
--capacity-scaler 1 \
--instance-group $MIG \
--instance-group-zone $ZONE \
--global
Create a backend bucket
BACKEND_BUCKET=ntireader-web-bucket-prod
gcloud compute backend-buckets create $BACKEND_BUCKET --gcs-bucket-name $BUCKET
URL_MAP=ntireader-map-prod
gcloud compute url-maps create $URL_MAP \
--default-backend-bucket $BACKEND_BUCKETCreate a serverless Network Endpoint Group for the Cloud Run deployment
NEG=[name of NEG]
gcloud compute network-endpoint-groups create $NEG \
--region=$REGION \
--network-endpoint-type=serverless \
--cloud-run-service=$SERVICECreate an LB backend service
LB_SERVICE=[name of service]
gcloud compute backend-services create $LB_SERVICE --globalAdd the NEG to the backend service
gcloud beta compute backend-services add-backend $LB_SERVICE \
--global \
--network-endpoint-group=$NEG \
--network-endpoint-group-region=$REGIONCreate a matcher for the NEG backend service
MATCHER_NAME=[your matcher name]
gcloud compute url-maps add-path-matcher $URL_MAP \
--default-backend-bucket $BACKEND_BUCKET \
--path-matcher-name $MATCHER_NAME \
--path-rules="/find/*=$LB_SERVICE,/findadvanced/*=$LB_SERVICE,/findmedia/*=$LB_SERVICE,/findsubstring=$LB_SERVICE,/findtm=$LB_SERVICE"MATCHER_NAME=ntireader-url-matcher-prod
gcloud compute url-maps add-path-matcher $URL_MAP \
--default-backend-bucket $BACKEND_BUCKET \
--path-matcher-name $MATCHER_NAME \
--path-rules="/find/*=$BACKEND_NAME,/findadvanced/*=$BACKEND_NAME,/findmedia/*,/findtm=$BACKEND_NAME"
TARGET_PROXY=ntireader-lb-proxy-prod
gcloud compute target-http-proxies create $TARGET_PROXY \
--url-map $URL_MAP
STATIC_IP=ntireader-web-prod
gcloud compute addresses create $STATIC_IP --global
FORWARDING_RULE=ntireader-content-rule-prod
gcloud compute forwarding-rules create $FORWARDING_RULE \
--address $STATIC_IP \
--global \
--target-http-proxy $TARGET_PROXY \
--ports 80Check the forwarding rule
gcloud compute forwarding-rules list
Troubleshooting: check the named port on the instance group.
Create an SSL cert
SSL_CERTIFICATE_NAME=ntireader-cert
DOMAIN=ntireader.org
gcloud beta compute ssl-certificates create $SSL_CERTIFICATE_NAME \
--domains $DOMAIN
Create a target proxy
SSL_TARGET_PROXY=ntireader-target-proxy-ssl
gcloud compute target-https-proxies create $SSL_TARGET_PROXY \
--url-map=$URL_MAP \
--ssl-certificates=$SSL_CERTIFICATE_NAME
Create a forwarding rule
STATIC_IP=34.98.80.193
SSL_FORWARDING_RULE=ntireader-forwarding-rule-prod-ssl
gcloud compute forwarding-rules create $SSL_FORWARDING_RULE \
--address $STATIC_IP \
--ports=443 \
--global \
--target-https-proxy $SSL_TARGET_PROXY
Run the term frequency analysis with Google Cloud Dataflow. Follow instructions at Chinese Text Reader
Create a GCP service account, download a key, and set it to the file:
export GOOGLE_APPLICATION_CREDENTIALS=${PWD}/dataflow-service-account.json
Set the location of the GCS bucket to read text from
TEXT_BUCKET=[your GCS bucket]
Use a different bucket for the Dataflow results and binaries:
DF_BUCKET=[your other GCS bucket]
Set the configuration environment variable
export CNREADER_HOME=${PWD}
From a higher directory, clone the cnreader Git project
cd ..
git clone https://github.com/alexamies/cnreader.git
CNREADER_PATH=${PWD}/cnreader
cd cnreader/tfidf
The GCP project:
PROJECT_ID=[your project id]Run the pipeline on Dataflow
cd ..
export CNREADER_PATH=${PWD}/cnreader
DATAFLOW_REGION=us-central1
CORPUS=ntireader
GEN=0
cd ${CNREADER_PATH}/tfidf
go run tfidf.go \
--input gs://${TEXT_BUCKET} \
--cnreader_home ${CNREADER_HOME} \
--corpus_fn data/corpus/collections.csv \
--corpus_data_dir data/corpus \
--corpus $CORPUS \
--generation $GEN \
--runner dataflow \
--project $PROJECT_ID \
--region $DATAFLOW_REGION \
--flexrs_goal=FLEXRS_COST_OPTIMIZED \
--staging_location gs://${DF_BUCKET}/binaries/
Track the job progress in the GCP console, as shown in the figure below.
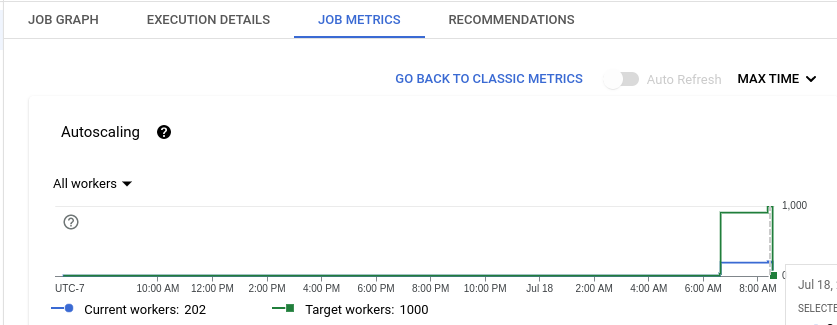
Consider removing the flag:
--flexrs_goal=FLEXRS_COST_OPTIMIZED
if the job is too slow.
Validation test:
cd $CNREADER_HOME
COLLECTION=taisho/t0007.html
$CNREADER_PATH/cnreader --test_index_terms "一者" \
--project ${PROJECT_ID} \
--collection ${COLLECTION} > output.txt 2>&1Set the project directory home
cd buddhist-dictionary
export CNREADER_HOME=${PWD}Generate the title database
$CNREADER_PATH/cnreader -titleindexSet the web application binary home:
cd ..
CNWEB_BIN_HOME=${PWD}/chinesenotes-goTry full text search in the web app
cd $CNREADER_HOME
export PROJECT_ID=$PROJECT_ID
export CNWEB_HOME=$CNREADER_HOME
$CNWEB_BIN_HOME/chinesenotes-go$CNREADER_PATH/cnreader --titleindex --project $PROJECT_IDAlso, generate a file for the document index, needed for the web app:
$CNREADER_PATH/cnreader --titleindex Run a search against the title index:
$CNREADER_PATH//cnreader --project $PROJECT_ID --titlesearch "本相猗致"Run a full text Search search:
export TEXT_BUCKET=ntinreader-text
$CNREADER_PATH/cnreader --project $PROJECT_ID --find_docs "本相猗致" --outfile results.csv > output.txt 2>&1To index the translation memory use the command
nohup $CNREADER_PATH/cnreader --project $PROJECT_ID --tmindex &Indexing may take about 12 hours.
Search the translation memory index
$CNREADER_PATH/cnreader --project $PROJECT_ID --tmsearch 古來世世經