Quality of Service
The section gives a simplified description of the path a packet goes through from the time it enters the ASIC until it is scheduled for transmission. It then continues to describe the various quality of service (QoS) mechanisms supported by the ASIC and how they affect the previously described path.
- Packet Forwarding
- Tools
- Priority Assignment
- Priority Group Buffers
- Configuring Lossless Traffic
- Traffic Scheduling
- DSCP Rewrite
- Shared Buffers
- Control Plane Policing (CoPP)
- Further Resources
When a packet enters the chip, it is assigned Switch Priority (SP), an internal identifier that informs how the packet is treated in context of other traffic. The assignment is made based on packet headers and switch configuration—see Priority Assignment for details.
Afterwards, the packet is directed to a priority group (PG) buffer in the port's headroom based on its SP. The port's headroom buffer is used to store incoming packets on the port while they go through the switch's pipeline and also to store packets in a lossless flow if they are not allowed to enter the switch's shared buffer. However, if there is no room for the packet in the headroom, it gets dropped. Mapping an SP to a PG buffer is explained in the Priority Group Buffers section.
Once outside the switch's pipeline, the packet's ingress port, internal SP, egress port, and traffic class (TC) are known. Based on these parameters the packet is classified to ingress and egress pools in the switch's shared buffer. In order for it to be eligible to enter the shared buffer, certain quotas associated with the packet need to be checked. These quotas and their configuration are described in the shared buffers section.
The packet stays in the shared buffer until it is transmitted from its designated egress port. The packet is queued for transmission according to its Traffic Class (TC). Once in its assigned queue, the packet is scheduled for transmission based on the chosen traffic selection algorithm (TSA) employed on the TC and its various parameters. The mapping from SP to TC and TSA configuration are discussed in the Traffic Scheduling section.
Packets which are not eligible to enter the shared buffer stay in the headroom if they are associated with a lossless flow (mapped to a lossless PG). Otherwise, they are dropped. The configuration of lossless flows is discussed in the Configuring Lossless Traffic section.
| Kernel Version | |
|---|---|
| 4.7 | Shared buffers, Trust PCP |
| 4.19 | Trust DSCP, DSCP rewrite, net.ipv4.ip_forward_update_priority
|
| Dedicated pool & TCs for BUM traffic | |
| 4.20 | BUM pool & TCs exposed in devlink-sb |
| Minimum shaper configured on BUM TCs | |
| 5.1 | Spectrum-2 support |
| 5.6 | Setting port-default priority |
| 5.7 | ACL-based priority assignment, ACL-based DSCP rewrite |
| 5.10 | Support for DCB buffer commands |
Quality of service on mlxsw is configured using predominantly three interfaces:
DCB, TC and devlink. All three can be configured through iproute2 tools.
Open LLDP can be used to configure DCB as well, and is covered together
with the iproute2 tool in this document.
For an overview of DCB and particularly DCB operation in Linux please refer to this article.
To enable DCB support in the mlxsw_spectrum driver,
CONFIG_MLXSW_SPECTRUM_DCB=y is needed.
iproute2 has had support for configuration of DCB through the dcb tool since
the release 5.11, although the app object has not been added until 5.12.
Open LLDP is a daemon that handles the LLDP protocol, and can configure individual stations in the LLDP network as to losslessness of traffic, egress traffic scheduling, and other attributes. Once run, it takes over the switch and manages individual interfaces through the Linux DCB interface.
For further information on LLDP support, it is advised to go over the LLDP document.
For most of the features, it is immaterial whether Open LLDP or iproute2 is
chosen. However the iproute2 tool has a more complete support, and e.g. DCB
buffer object can currently not be configured through Open LLDP.
Switch Priority (SP) of a packet can be derived from packet headers, or assigned
by default. Which headers are used when deriving SP of a packet depends on
configuration of Trust Level of the port through which a given packet ingresses.
mlxsw currently recognizes two trust levels: "Trust PCP" (or Trust L2; this is
the default) and "Trust DSCP" (or Trust L3).
Note: In Linux, packets are stored in a data structure called socket buffer
(SKB). One of the fields of the SKB is the priority field. In the ASIC,
the entity corresponding to SKB priority is the Switch Priority (SP). Note that
these two values, SKB priority and Switch priority, are distinct, and the Switch
priority assigned to a packet is not projected to the SKB priority. If
forwarding of part of the traffic is handled on the CPU, and traffic
prioritization is important, SKBs need to be assigned priority anew, e.g. using
software tc filters.
By default, ports are in trust-PCP mode. In that case, the switch will prioritize a packet based on its IEEE 802.1p priority. This priority is specified in the packet's Priority Code Point (PCP) field, which is part of the packet's VLAN header. The mapping between PCP and SP is 1:1 and cannot be changed.
If the packet does not have 802.1p tagging, it is assigned port-default priority.
Each port can be configured to set Switch Priority of packets based on the DSCP field of IP and IPv6 headers. The priority is assigned to individual DSCP values through the DCB APP entries.
After the first APP rule is added for a given port, this port's trust level is toggled to DSCP. It stays in this mode until all DSCP APP rules are removed again.
Use dcb app attribute dscp-prio to manage the DSCP APP entries:
$ dcb app add dev <port> dscp-prio <DSCP>:<SP> # Insert rule.
$ dcb app del dev <port> dscp-prio <DSCP>:<SP> # Delete rule.
$ dcb app show dev <port> dscp-prio # Show rules.
For example, to assign priority 3 to packets with DSCP 24 (symbolic name CS3):
$ dcb app add dev swp1 dscp-prio 24:3 # Either using numerical value
$ dcb app add dev swp1 dscp-prio CS3:3 # Or using symbolic name
$ dcb app show dev swp1 dscp-prio
dscp-prio CS3:3
$ dcb -N app show dev swp1 dscp-prio
dscp-prio 24:3
In Open LLDP, the DCB APP entries are configured as follows:
$ lldptool -T -i <port> -V APP app=<SP>,5,<DSCP> # Insert rule.
$ lldptool -T -i <port> -V APP -d app=<SP>,5,<DSCP> # Delete rule.
$ lldptool -t -i <port> -V APP -c app # Show rules.
Note: The support for the DSCP APP rules in openlldpad was introduced by this patch. If the above commands give a "selector out of range" error, the reason is that the package that you are using does not carry the patch.
Note: The use of selector 5 is described in the draft standard 802.1Qcd/D2.1 Table D-9.
The Linux DCB interface allows a very flexible configuration of DSCP-to-SP mapping, to the point of permitting configuration of two priorities for the same DSCP value. These conflicts are resolved in favor of the highest configured priority. For example:
$ dcb app add dev swp1 dscp-prio 24:3 # Configure 24->3.
$ dcb app add dev swp1 dscp-prio 24:2 # Keep 24->3.
$ dcb app show dev swp1 dscp-prio
dscp-prio CS3:2 CS3:3
$ dcb app del dev swp1 dscp-prio 24:3 # Configure 24->2.
dcb has syntax sugar for the above sequence in the form of the replace
command. The following runs the exact same set of DCB commands under the hood:
$ dcb app replace dev swp1 dscp-prio 24:3 # Configure 24->3.
$ dcb app replace dev swp1 dscp-prio 24:2 # Configure 24->2.
When a packet arrives with a DSCP value that does not have a corresponding APP rule, or a non-IP packet arrives, it is assigned port-default priority instead.
Trust-DSCP mode disables PCP prioritization even for non-IP packets that have no DSCP value, and even if they have 802.1p tagging. Such packets get the port-default priority assigned instead.
Note: The Spectrum chip supports also a "trust both" mode, where Switch
Priority is assigned based on PCP when DSCP is not available, however this mode
is currently not supported by mlxsw.
A default value is assigned to packet's SP when:
- it does not have an 802.1p tagging and ingresses through a trust-PCP port
- it is a non-IPv4/non-IPv6 packet and ingresses through a trust-DSCP port
The default value for port-default priority is 0. It can however be configured
similarly to how the DSCP-to-priority mapping is. As with the DSCP APP rules,
Linux allows configuration of several default priorities. Again, mlxsw chooses
the highest one that is configured.
Use dcb app attribute default-prio to configure the default priority:
$ dcb app add dev <port> default-prio <SP> # Insert rule for default priority <SP>.
$ dcb app del dev <port> default-prio <SP> # Delete rule for default priority <SP>.
$ dcb app replace dev <port> default-prio <SP> # Set default priority to <SP>.
When using Open LLDP, this is configured as an "APP" rule with selector 1 (Ethertype) and PID 0, which denote "default application priority [...] when application priority is not otherwise specified":
$ lldptool -T -i <port> -V APP app=<SP>,1,0 # Insert rule for default priority <SP>.
$ lldptool -T -i <port> -V APP -d app=<SP>,1,0 # Delete rule for default priority <SP>.
Note: The use of selector 1 is standardized in 802.1Q-2014 in Table D-9.
Spectrum switches allow overriding in the ACL engine the prioritization decision
described in the previous paragraphs. The ACLs page talks about how to
configure filters. In order to change packet priority, use the action skbedit priority:
$ tc filter add dev swp1 ingress flower action skbedit priority 5
In the SW datapath, it is possible to assign arbitrary priorities and use the
skbedit priority action to select a particular traffic class, but this usage
is not offloaded. Only priorities 0-7 are currently allowed for the HW datapath.
The priority override is allowed both on ingress and on egress of a netdevice.
Note: The priority override only happens after the packet's priority group is resolved, and does not change this decision. Therefore when changing from a lossless priority to a lossy one, the now-lossy packet is still subject to flow control, and vice versa. When changing from one lossless priority to another, the flow control is performed on the wrong priority. Therefore the only reprioritization that works and is supported is from one lossy priority to another lossy priority. This is a HW limitation.
In Linux, the priority of forwarded IPv4 SKBs is updated according to the TOS
value in IPv4 header. The mapping is fixed, and cannot be configured. mlxsw
configures the switch to update packet priority after routing as well using the
same values. However unlike the software path, this is done for both IPv4 and
IPv6.
Note: The actual mapping from TOS to SKB priority is shown in man tc-prio, section "QDISC PARAMETERS", parameter "priomap".
As of 4.19, it is possible to turn this behavior off through sysctl:
$ sysctl -w net.ipv4.ip_forward_update_priority=0
This disables IPv4 priority update after forwarding in slow path, as well as both IPv4 and IPv6 post-routing priority update in the chip. In other words, when this sysctl is cleared the priority assigned to a packet at ingress will be preserved after the packet is routed.
Priority group buffers (PG buffers) are the area of the switch shared buffer where packets are kept while they go through the switch's pipeline. For lossless flows, this is also the area where traffic is kept before it can be admitted to the shared buffer.
After packet priority is assigned through the trust PCP, trust DSCP or default priority mechanisms, the switch inspects priority map for the port, and determines which PG buffer should host a given packet. PGs 0 to 7 can be configured this way. PG8 is never used and control traffic is always directed to PG9.
Note: changing the priority in the ACL and in the router does not impact PG selection.
The way the PG buffers and priority map are configured depends on the way that the port egress is configured. The rest of this section describes the details.
The Spectrum ASIC allocates the chip memory in units of cells. Cell size depends
on a particular chip, and is reported by devlink:
$ devlink sb pool show
pci/0000:03:00.0:
sb 0 pool 0 type ingress size 13768608 thtype dynamic cell_size 96
[...]
Computed or requested buffer sizes are rounded up to the nearest cell size boundary.
When traffic scheduling on the port is configured using the DCB ETS commands, the port is in DCB mode.
In that case, buffer sizes of PGs 0-7 are configured automatically. Unused buffers will have a zero size.
Priority map is deduced from the ETS priority map, as mapping different flows to different TCs at egress also implies that they should be separated at ingress.
E.g. the following command will, in addition to the egress configuration, configure headroom priority map such that traffic with priorities 0-3 is assigned to PG0, and traffic with priorities 4-7 to PG1:
$ dcb ets set dev swp1 prio-tc {0..3}:0 {4..7}:1
Use dcb buffer to inspect the buffer configuration:
$ dcb buffer show dev swp1
prio-buffer 0:0 1:0 2:0 3:0 4:1 5:1 6:1 7:1 <-- priority map
buffer-size 0:3Kb 1:3Kb 2:0b 3:0b 4:0b 5:0b 6:0b 7:0b
total-size 16416b
Note: The interface only allows showing the size of the first 8 PG buffers,
out of the total of 10 buffers and internal mirroring buffer that the Spectrum
ASIC has. The reported total_size shows the full allocated size of the
headroom, including these hidden components, and therefore is not a simple sum
of the individual PG buffer sizes.
When egress traffic scheduling is configured using
qdiscs, the port transitions to TC mode. In this
mode, the sizes of PG buffers are configured by hand using dcb buffer:
$ dcb buffer set dev swp1 buffer-size all:0 0:25K 1:25K
Note: There is a minimum allowed size for a used PG buffer. The system will always configure at least this minimum size, which is equal to the Xoff threshold.
The priority map is also configured directly, through the dcb buffer command:
$ dcb buffer set dev swp1 prio-buffer {0..3}:0 {4..7}:1
And to inspect the configuration:
$ dcb buffer show dev swp1
prio-buffer 0:0 1:0 2:0 3:0 4:1 5:1 6:1 7:1
buffer-size 0:25632b 1:25632b 2:0b 3:0b 4:0b 5:0b 6:0b 7:0b
total-size 61536b
Note: As above, total_size is not a simple sum of shown PG
sizes.
Note: Configuration of the sizes of PG buffers and priority map while the port is in DCB mode is forbidden.
Packets which are not eligible to enter the shared buffer can stay in the
headroom, if they are associated with a lossless flow. To configure a PG as
lossless use dcb pfc attribute prio-pfc. For example, to enable PFC for
priorities 1, 2 and 3, run:
$ dcb pfc set dev swp1 prio-pfc all:off 1:on 2:on 3:on
$ dcb pfc show dev swp1 prio-pfc
prio-pfc 0:off 1:on 2:on 3:on 4:off 5:off 6:off 7:off
This command enables PFC for both Rx and Tx.
In Open LLDP, this is configured through the enabled attribute of PFC TLV
using lldptool:
$ lldptool -T -i swp1 -V PFC enabled=1,2,3
Note: Setting a priority as lossless and mapping it to a PG buffer along with lossy priorities yields unpredictable behavior.
Besides enabling PFC, Shared Buffers need to be configured suitably as well. Packets associated with a lossless flow can only stay in the headroom if the following conditions hold:
-
The per-Port and per-{Port, TC} quotas of the egress port are set to the maximum allowed value.
-
When binding a lossless PG to a pool, the size of the pool and the quota assigned to the {Port, PG} must be non-zero.
Note: The threshold type of the default egress pool (pool #4) is dynamic and cannot be changed. Therefore, when PFC is enabled a different egress pool needs to be used.
Packets with PFC-enabled priorities are allowed to stay in their assigned PG buffer in the port's headroom, but if the PG buffer is full they are dropped. To prevent that from happening, there is a point in the PG buffer called the Xoff threshold. Once the amount of traffic in the PG reaches that threshold, the switch sends a PFC packet telling the transmitter to stop sending (Xoff) traffic for all the priorities sharing this PG. Once the amount of data in the PG buffer goes below the threshold, a PFC packet is transmitted telling the other side to resume transmission (Xon) again.
The Xon/Xoff threshold is autoconfigured and always equal to 2*(MTU rounded up to cell size). Furthermore, 8-lane ports (regardless of the negotiated number of lanes) use two buffers among which the configured value is split, and the Xoff threshold size thus needs to be doubled again.
Even after sending the PFC packet, traffic will keep arriving until the transmitter receives and processes the PFC packet. This amount of traffic is known as the PFC delay allowance.
In DCB mode, the delay allowance can be configured through dcb pfc
attribute delay:
$ dcb pfc set dev swp1 delay 32768
When using Open LLDP, this can be set by using the PFC delay key:
$ lldptool -T -i swp1 -V PFC delay=32768
Maximum delay configurable through this interface is 65535 bit.
Note: In the worst case scenario the delay will be made up of packets that are all of size that is one byte larger than the cell size, which means each packet will require almost twice its true size when buffered in the switch. Furthermore, when the PAUSE or PFC frame is received, the host already may have started transmitting another MTU-sized frame. The full formula for delay allowance size therefore is 2 * (delay in bytes rounded up to cell size) + (MTU rounded up to cell size).
In TC mode, instead of configuring the delay allowance, the PG buffer size is set exactly. The Xoff is still autoconfigured, and whatever is above the Xoff mark is the delay allowance.
The resulting PG buffer:
+----------------+ +
| | |
| | |
| | |
| | |
| | |
| | | Delay
| | |
| | |
| | |
| | |
| | |
Xon/Xoff threshold +----------------+ +
| | |
| | | 2 * MTU
| | |
+----------------+ +
If packets continue to be dropped, then the delay value should be increased. The Xoff threshold is always autoconfigured.
For PFC to work properly, both sides of the link need to be configured
correctly. One can use dcb pfc on the remote end in the same way that it is
used on the switch. However, if LLDP is used, it can take care of configuring
the remote end. Run:
$ lldptool -T -i swp1 -V PFC willing=no
$ lldptool -T -i swp1 -V PFC enableTx=yes
And on the host connected to the switch:
$ lldptool -T -i enp6s0 -V PFC willing=yes
When the host receives the switch's PFC TLV, it will use its settings:
host$ lldptool -t -i enp6s0 -V PFC
IEEE 8021QAZ PFC TLV
Willing: yes
MACsec Bypass Capable: no
PFC capable traffic classes: 8
PFC enabled: 1 2 3
When a PFC packet is received by a port, it stops the TCs to which the priorities set in the PFC packet are mapped.
Note: A PFC packet received for a PFC enabled priority stops lossy priorities from transmitting if they are mapped to the same TC as the lossless priority.
To enable PAUSE frames on a port, run:
$ ethtool -A swp1 autoneg off rx on tx on
To query PAUSE frame parameters, run:
$ ethtool -a swp1
Pause parameters for swp1
Autonegotiate: off
RX: on
TX: on
Unlike PFC configuration, it is not possible to set the delay parameter. Therefore, this delay is hardcoded as 155 Kbit. This is larger than what PFC allows, and is set according to a worst-case scenario of 100m cable. Due to this setting, if too many PG buffers are used and MTU is too large, the configuration may not fit to the port headroom limits, and may be rejected. E.g.:
$ dcb ets set dev swp1 prio-tc 0:0 1:1 2:2 3:3 4:4 5:5 6:6 7:7
$ ethtool -A swp1 autoneg off rx on tx on
$ ip link set dev swp1 mtu 10000
RTNETLINK answers: No buffer space available
Note: It is not possible to have both PFC and PAUSE frames enabled on a port at the same time. Trying to do so generates an error.
Enhanced Transmission Selection (ETS) is an 802.1q-standardized way of assigning available bandwidth to traffic lined up to egress through a given port. Based on priority (Switch priority in case of the HW datapath), each packet is put in one of several available queues, called traffic classes (TCs).
mlxsw supports two interfaces to configure traffic scheduling: DCB (described
here) and TC. It is necessary to choose one of these
approaches and stick to it. Configuring qdiscs will overwrite the DCB
configuration present at the time, and configuring DCB will overwrite qdisc
configuration.
When the forwarding pipeline determines the egress port of a packet, Switch priority together with the priority map is used to decide which TC the packet should be put to.
Use dcb ets attribute prio-tc to configure the priority map:
$ dcb ets set dev swp1 prio-tc 0:0 1:1 2:2 3:3 4:4 5:5 6:6 7:7
The above command creates 1:1 mapping from SP to TC. In addition, as explained elsewhere, the command creates 1:1 mapping between SP and PG buffer.
With Open LLDP, use the ETS-CFG TLV's up2tc field. E.g.:
$ lldptool -T -i swp1 -V ETS-CFG up2tc=0:0,1:1,2:2,3:3,4:4,5:5,6:6,7:7
When assigning bandwidth to the queued-up traffic, the switch takes into account
what transmission selection algorithm (TSA) is configured on each TC. mlxsw
supports two TSAs: the default Strict Priority algorithm, and ETS.
When selecting packets for transmission, strict TCs are tried first, in the order of decreasing TC index. When there is no more traffic in any of the strict bands, bandwidth is distributed among the traffic from the ETS bands according to their configured weights.
The TSAs can be configured through the tc-tsa attribute:
$ dcb ets set dev swp1 tc-tsa all:strict
With Open LLDP, TSAs are configured through the ETS-CFG TLV's tsa field. For
example:
$ lldptool -T -i swp1 -V ETS-CFG \
tsa=0:strict,1:strict,2:strict,3:strict,4:strict,5:strict,6:strict,7:strict
ETS is implemented in the ASIC using a weighted round robin (WRR)
algorithm. The device requires that the sum of the weights used amounts to
100. Otherwise, changes do not take effect. Thus when configuring TSAs to use
ETS, it is typically also necessary to adjust bandwidth percentage allotment.
This is done through dcb ets attribute tc-bw:
$ dcb ets set dev swp1 tc-tsa all:ets tc-bw {0..3}:12 {4..7}:13
$ dcb ets show dev swp1 tc-tsa tc-bw
tc-tsa 0:ets 1:ets 2:ets 3:ets 4:ets 5:ets 6:ets 7:ets
tc-bw 0:12 1:12 2:12 3:12 4:13 5:13 6:13 7:13
In Open LLDP that is done through ETS-CFG TLV's tcbw field, whose argument
is a list of bandwidth allotments, one for each TC:
$ lldptool -T -i swp1 -V ETS-CFG \
tsa=0:ets,1:ets,2:ets,3:ets,4:ets,5:ets,6:ets,7:ets \
tcbw=12,12,12,12,13,13,13,13
In case of a congestion, if the criteria for admission of a packet to shared buffer are not met, and the packet in question is not in a lossless PG, it will be dropped. That is the case even if that packet is of higher priority or mapped to a higher-precedence TC than the ones already admitted to the shared buffer. In other words, once the packet is in the shared buffer, there is no way to punt it except through blunt tools such as Switch Lifetime Limit.
It is therefore necessary to configure pool sizes and quotas in such a way that there is always room for high-priority traffic to be admitted.
To allow neighbouring hosts to know about the ETS configuration when using LLDP, run:
$ lldptool -T -i swp1 -V ETS-CFG enableTx=yes
This can be verified on a neighbouring host by running:
host$ lldptool -i enp6s0 -n -t -V ETS-CFG
IEEE 8021QAZ ETS Configuration TLV
Willing: yes
CBS: not supported
MAX_TCS: 8
PRIO_MAP: 0:0 1:1 2:2 3:3 4:4 5:5 6:6 7:7
TC Bandwidth: 12% 12% 12% 12% 13% 13% 13% 13%
TSA_MAP: 0:ets 1:ets 2:ets 3:ets 4:ets 5:ets 6:ets 7:ets
Packets that ingress the switch through a port that is in trust-DSCP mode, will have their DSCP value updated as they egress the switch. The same DSCP APP rules that are used for packet prioritization are used to configure the rewrite as well. If several priorities end up resolving to the same DSCP value (as they probably will), the highest DSCP is favored. For example:
$ dcb app add dev swp1 dscp-prio 26:3 # Configure 3->26
$ dcb app add dev swp1 dscp-prio 24:3 # Keep 3->26
$ dcb app del dev swp1 dscp-prio 26:3 # Configure 3->24
If there is no rule matching the priority of a packet, DSCP of that packet is rewritten to zero. As a consequence, if there are no rules at all configured at the egress port, all DSCP values are rewritten to zero.
It is worth repeating that the decision to rewrite is made as the packet ingresses the switch through a trust-DSCP port, however the rewrite map to use is taken from the egress port.
As a consequence, in mixed-trust switches, if a packet ingresses through a trust-PCP port, and egresses through a trust-DSCP port, its DSCP value will stay intact. That means that a DSCP value can leak from one domain to another, where it may have a different meaning. Therefore when running a switch with a mixture of trust levels, one needs to be careful that this is not a problem.
Spectrum switches allow rewriting packet's DSCP value in the ACL engine. The
ACLs page talks about how to configure filters. In order to change packet
DSCP, add a filter with the action pedit. For
IPv4 like this:
$ tc filter add dev swp1 ingress prot ip flower skip_sw \
action pedit ex munge ip tos set $((dscp << 2)) retain 0xfc
And for IPv6 like this:
$ tc filter add dev swp1 ingress prot ipv6 flower skip_sw \
action pedit ex munge ip6 traffic_class set $((dscp << 2)) retain 0xfc
The packets whose DSCP value is rewritten this way are not subject to the DSCP rewrite described above.
As explained above, packets are admitted to the switch's shared buffer from the port's headroom and stay there until they are transmitted out of the switch.
The device has two types of pools, ingress and egress. The pools are used as containers for packets and allow a user to limit the amount of traffic:
- From a port
- From a {Port, PG buffer}
- To a port
- To a {Port, TC}
The limit can be either a specified amount of bytes (static) or a percentage of the remaining free space (dynamic).
Once out of the switch's pipeline, a packet is admitted into the shared buffer only if all four quotas mentioned above are below the configured threshold:
Ingress{Port}.Usage < ThresIngress{Port,PG}.Usage < ThresEgress{Port}.Usage < ThresEgress{Port,TC}.Usage < Thres
A packet admitted to the shared buffer updates all four usages.
To configure a pool's size and threshold type, run:
$ devlink sb pool set pci/0000:03:00.0 pool 0 size 12401088 thtype dynamic
To see the current settings of a pool, run:
$ devlink sb pool show pci/0000:03:00.0 pool 0
Note: Control packets (e.g. LACP, STP) use ingress pool number 9 and cannot be bound to a different pool. It is therefore important to configure it using a suitable size. Prior to kernel 5.2 such packets were using ingress pool number 3.
Limiting the usage of a flow in a pool can be done by using either a static or dynamic threshold. The threshold type is a pool property and is set as follows:
$ devlink sb pool set pci/0000:03:00.0 pool 0 size 12401088 thtype static
To set a dynamic threshold, run:
$ devlink sb pool set pci/0000:03:00.0 pool 0 size 12401088 thtype dynamic
To bind packets originating from a {Port, PG} to an ingress pool, run:
$ devlink sb tc bind set pci/0000:03:00.0/1 tc 0 type ingress pool 0 th 9
Or use port name instead:
$ devlink sb tc bind set swp1 tc 0 type ingress pool 0 th 9
If the pool's threshold is dynamic, then the value specified as the threshold
is used to calculate the alpha parameter:
alpha = 2 ^ (th - 10)
The range of the passed value is between 3 and 16. The computed alpha is used
to determine the maximum usage of the flow according to the following formula:
max_usage = alpha / (1 + alpha) * Free_Buffer
Where Free_Buffer is the amount of non-occupied buffer in the relevant pool.
The following table shows the possible th values and their corresponding
maximum usage:
| th | alpha | max_usage |
|---|---|---|
| 3 | 0.0078125 | 0.77% |
| 4 | 0.015625 | 1.53% |
| 5 | 0.03125 | 3.03% |
| 6 | 0.0625 | 5.88% |
| 7 | 0.125 | 11.11% |
| 8 | 0.25 | 20% |
| 9 | 0.5 | 33.33% |
| 10 | 1 | 50% |
| 11 | 2 | 66.66% |
| 12 | 4 | 80% |
| 13 | 8 | 88.88% |
| 14 | 16 | 94.11% |
| 15 | 32 | 96.96% |
| 16 | 64 | 98.46% |
To see the current settings of binding of {Port, PG} to an ingress pool, run:
$ devlink sb tc bind show swp1 tc 0 type ingress
swp1: sb 0 tc 0 type ingress pool 0 threshold 10
Similarly for egress, to bind packets directed to a {Port, TC} to an egress pool, run:
$ devlink sb tc bind set swp1 tc 0 type egress pool 4 th 9
If the pool's threshold is static, then its value is treated as the maximum number of bytes that can be used by the flow.
The admission rule requires that the port's usage is also smaller than the maximum usage. To set a threshold for a port, run:
$ devlink sb port pool set swp1 pool 0 th 15
The static threshold can be used to set minimal and maximal usage. To set minimal usage, the static threshold should be set to 0, in which case the flow never enters the specified pool. Maximal usage can be configured by setting the threshold to the pool's size or larger.
It is possible to take a snapshot of the shared buffer usage with the following command:
$ devlink sb occupancy snapshot pci/0000:03:00.0
Once the snapshot is taken, the user may query the current and maximum usage by:
- Pool
- {Port, Pool}
- {Port, PG}
- {Port, TC}
This is especially useful when trying to determine optimal sizes and thresholds.
Note: The snapshot is not atomic. However, the interval between the different measurements composing it is as minimal as possible, thus making the snapshot as accurate as possible.
Note: Queries following a failed snapshot are invalid.
To monitor the current and maximum occupancy of a port in a pool and to display current and maximum usage of {Port, PG/TC} in a pool, run:
$ devlink sb occupancy show swp1
swp1:
pool: 0: 0/0 1: 0/0 2: 0/0 3: 0/0
4: 0/0 5: 0/0 6: 0/0 7: 0/0
8: 0/0 9: 0/0 10: 0/0
itc: 0(0): 0/0 1(0): 0/0 2(0): 0/0 3(0): 0/0
4(0): 0/0 5(0): 0/0 6(0): 0/0 7(0): 0/0
etc: 0(4): 0/0 1(4): 0/0 2(4): 0/0 3(4): 0/0
4(4): 0/0 5(4): 0/0 6(4): 0/0 7(4): 0/0
8(8): 0/0 9(8): 0/0 10(8): 0/0 11(8): 0/0
12(8): 0/0 13(8): 0/0 14(8): 0/0 15(8): 0/0
For the CPU port, run:
$ devlink sb occupancy show pci/0000:03:00.0/0
pci/0000:03:00.0/0:
pool: 0: 0/0 1: 0/0 2: 0/0 3: 0/0
4: 0/0 5: 0/0 6: 0/0 7: 0/0
8: 0/0 9: 0/0 10: 0/0
itc: 0(0): 0/0 1(0): 0/0 2(0): 0/0 3(0): 0/0
4(0): 0/0 5(0): 0/0 6(0): 0/0 7(0): 0/0
etc: 0(10): 0/0 1(10): 0/0 2(10): 0/0 3(10): 0/0
4(10): 0/0 5(10): 0/0 6(10): 0/0 7(10): 0/0
8(10): 0/0 9(10): 0/0 10(10): 0/0 11(10): 0/0
12(10): 0/0 13(10): 0/0 14(10): 0/0 15(10): 0/0
Where pci/0000:03:00.0/0 represents the CPU port.
Note: For the CPU port, the egress direction represents traffic trapped to the CPU. The ingress direction is reserved.
To clear the maximum usage (watermark), run:
$ devlink sb occupancy clearmax pci/0000:03:00.0
A new maximum usage is tracked from the time the clear operation is performed.
Flood traffic is subject to special treatment by the ASIC. Such traffic is commonly referred to as BUM, for broadcast, unknown-unicast and multicast packets. BUM traffic is prioritized and scheduled separately from other traffic, using egress TCs 8–15, as opposed to TCs 0–7 for unicast traffic. Thus packets that would otherwise be assigned to some TC X, are assigned to TC X+8 instead, if they are BUM packets.
The pairs of unicast and corresponding BUM TCs are then configured to strictly prioritize the unicast traffic: TC 0 is strictly prioritized over TC 8, 1 over 9, etc. This configuration is necessary to mitigate an issue in Spectrum chips where an overload of BUM traffic shuts all unicast traffic out of the system.
However, strictly prioritizing unicast traffic has, under sustained unicast overload, the effect of blocking e.g. ARP traffic. These packets are admitted to the system, stay in the queues for a while, but if the lower-numbered TC stays occupied by unicast traffic, their lifetime eventually expires, and these packets are dropped. To prevent this scenario, a minimum shaper of 200Mbps is configured on the higher-numbered TCs to allow through a guaranteed trickle of BUM traffic even under unicast overload.
By default, one ingress pool (0) and one egress pool (4) are used for most of the traffic. In addition to that, pool 8 is dedicated for BUM traffic.
Pools 9 and 10 are also special and are used for traffic trapped to the CPU. Specifically, pool 9 is used for accounting of incoming control packets such as STP and LACP that are trapped to the CPU. Pool 10 is an egress pool used for accounting of all the packets that are trapped to the CPU.
Two types of pools (ingress and egress) are required because from the point of view of the shared buffer, traffic that is trapped to the CPU is like any other traffic. Such traffic enters the switch from a front panel port and transmitted through the CPU port, which does not have a corresponding netdev. Instead of being put on the wire, such packets cross the bus (e.g., PCI) towards the host CPU.
The major difference in the default configuration between Spectrum-1 and Spectrum-2 is the size of the shared buffer as can be seen in the output below.
Spectrum-1:
$ devlink sb pool show
pci/0000:01:00.0:
sb 0 pool 0 type ingress size 12440064 thtype dynamic cell_size 96
sb 0 pool 1 type ingress size 0 thtype dynamic cell_size 96
sb 0 pool 2 type ingress size 0 thtype dynamic cell_size 96
sb 0 pool 3 type ingress size 0 thtype dynamic cell_size 96
sb 0 pool 4 type egress size 13232064 thtype dynamic cell_size 96
sb 0 pool 5 type egress size 0 thtype dynamic cell_size 96
sb 0 pool 6 type egress size 0 thtype dynamic cell_size 96
sb 0 pool 7 type egress size 0 thtype dynamic cell_size 96
sb 0 pool 8 type egress size 15794208 thtype static cell_size 96
sb 0 pool 9 type ingress size 256032 thtype dynamic cell_size 96
sb 0 pool 10 type egress size 256032 thtype dynamic cell_size 96
Spectrum-2:
$ devlink sb pool show
pci/0000:06:00.0:
sb 0 pool 0 type ingress size 40960080 thtype dynamic cell_size 144
sb 0 pool 1 type ingress size 0 thtype static cell_size 144
sb 0 pool 2 type ingress size 0 thtype static cell_size 144
sb 0 pool 3 type ingress size 0 thtype static cell_size 144
sb 0 pool 4 type egress size 40960080 thtype dynamic cell_size 144
sb 0 pool 5 type egress size 0 thtype static cell_size 144
sb 0 pool 6 type egress size 0 thtype static cell_size 144
sb 0 pool 7 type egress size 0 thtype static cell_size 144
sb 0 pool 8 type egress size 41746464 thtype static cell_size 144
sb 0 pool 9 type ingress size 256032 thtype dynamic cell_size 144
sb 0 pool 10 type egress size 256032 thtype dynamic cell_size 144
Spectrum-3:
$ devlink sb pool show
pci/0000:07:00.0:
sb 0 pool 0 type ingress size 60561360 thtype dynamic cell size 144
sb 0 pool 1 type ingress size 0 thtype static cell size 144
sb 0 pool 2 type ingress size 0 thtype static cell size 144
sb 0 pool 3 type ingress size 0 thtype static cell size 144
sb 0 pool 4 type egress size 60561360 thtype dynamic cell size 144
sb 0 pool 5 type egress size 0 thtype static cell size 144
sb 0 pool 6 type egress size 0 thtype static cell size 144
sb 0 pool 7 type egress size 0 thtype static cell size 144
sb 0 pool 8 type egress size 60817536 thtype static cell size 144
sb 0 pool 9 type ingress size 256032 thtype dynamic cell size 144
sb 0 pool 10 type egress size 256032 thtype dynamic cell size 144
The shared buffers described above are used for storing of traffic payload.
Besides that, Spectrum machines have a separate resource for packet metadata, or
"descriptors". Descriptor buffer configuration is not exposed. All traffic is
currently configured to use descriptor pool 14. As of Linux 5.19, mlxsw
configures this pool to be "infinite", meaning all the available chip resources
can be used by traffic. Prior to 5.19, the default configuration has been used,
which was actually smaller.
Lack of descriptor buffer space can be observed as packets being rejected for
"no buffer space", e.g. the tc_no_buffer_discard_uc_tc ethtool counters,
without the corresponding pressure in the byte pools, as reported by devlink sb occupancy. A workload that would cause such exhaustion is traffic pressure
caused by a flow with many small packets.
The descriptor pool size is chip-dependent and the following table shows the number of descriptors available:
| ASIC | Descriptors |
|---|---|
| Spectrum-1 | 81920 |
| Spectrum-2 | 136960 |
| Spectrum-3 | 204800 |
The mlxsw driver is capable of reflecting the kernel's data path to
the Spectrum ASICs. This allows packets to be forwarded between front
panel ports without ever reaching the CPU.
While the data plane is offloaded to the ASIC, the control plane is still running on the CPU and is responsible for important tasks such as maintaining IP neighbours and delivering locally received packets to relevant user space applications (e.g., a routing daemon).
To ensure that the control plane receives the packets it needs, the ASIC contains various packet traps that are responsible for delivering such packets to the CPU. Refer to this page for the complete list.
Since the ASIC is capable of handling packet rates that are several orders of magnitude higher compared to those that can be handled by the CPU, the ASIC includes packet trap policers to prevent the CPU from being overwhelmed. These policers are bound to packet trap groups, which are used to aggregate logically related packet traps.
The default binding is set by the driver during its initialization and can be queried using the following command:
$ devlink trap group
pci/0000:01:00.0:
name l2_drops generic true policer 1
name l3_drops generic true policer 1
name l3_exceptions generic true policer 1
name tunnel_drops generic true policer 1
name acl_drops generic true policer 1
name stp generic true policer 2
name lacp generic true policer 3
name lldp generic true policer 4
name mc_snooping generic true policer 5
name dhcp generic true policer 6
name neigh_discovery generic true policer 7
name bfd generic true policer 8
name ospf generic true policer 9
name bgp generic true policer 10
name vrrp generic true policer 11
name pim generic true policer 12
name uc_loopback generic true policer 13
name local_delivery generic true policer 14
name ipv6 generic true policer 15
name ptp_event generic true policer 16
name ptp_general generic true policer 17
name acl_sample generic true
name acl_trap generic true policer 18
To change the default binding and police, for example, BGP and BFD packets using the same policer, run:
$ devlink trap group set pci/0000:01:00.0 group bgp policer 8
To unbind a policer use the nopolicer keyword:
$ devlink trap group set pci/0000:01:00.0 group bgp nopolicer
To query the parameters of policer 8, run:
$ devlink trap policer show pci/0000:01:00.0 policer 8
pci/0000:01:00.0:
policer 8 rate 20480 burst 1024
To set its rate to 5,000 packets per second (pps) and burst size to 256 packets, run:
$ devlink trap policer set pci/0000:01:00.0 policer 8 rate 5000 burst 256
When trapped packets exceed the policer's rate or burst size, they are
dropped by the policer. To query the number of packets dropped by
policer 8, run:
$ devlink -s trap policer show pci/0000:01:00.0 policer 8
pci/0000:01:00.0:
policer 8 rate 5000 burst 256
stats:
rx:
dropped 13522938
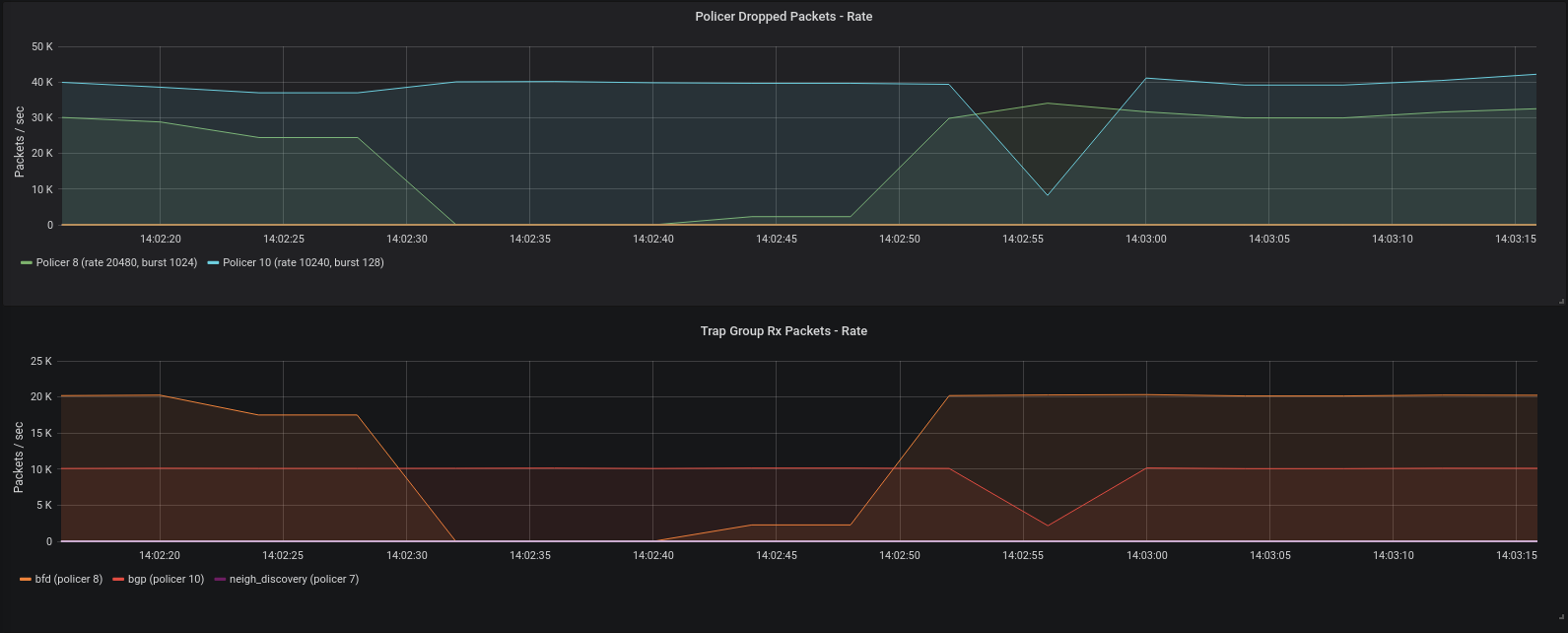
Prometheus is a popular time series database used for event monitoring and alerting. Its main component is the Prometheus server which periodically scrapes and stores time series data. The data is scraped from various exporters that export their metrics over HTTP.
Using devlink-exporter it is possible to export packets and
bytes statistics about each trap and trap group to Prometheus. In
addition, it is possible to export the number of packets dropped by each
trap policer.
Grafana can then be used to visualize the information:
- Wikipedia article on DCB
- man lldptool-ets
- man lldptool-pfc
- man lldptool-app
- man ethtool
- man devlink
- man devlink-sb
- man devlink-trap
- man dcb
- man dcb-app
- man dcb-buffer
- man dcb-ets
- man dcb-pfc