Learned image compression is a promising field fueled by the recent breakthroughs in Deep Learning and Information Theory. In this repo, a basic architecture for learned image compression will be shown along with the main building blocks and the hyperparameters of the network with a results discussion and comparison to the state-of-the-art BPG traditional codec.
The Kodak Dataset is used as a standard test suite for compression testing. We were able to achieve around a 104:1 compression ratio which is approximately 0.23 bpp. The results will be shown in a triplet format consisting of the original image, our result, and a BPG compressed image at the same bpp.




-
Download the pretrained model weights from the following link and place it in the same directory as the other files https://drive.google.com/file/d/1m-kJzcKYwo5X2t4vo1JM1Vkr1mrQ1cWW/view?usp=sharing
-
For compression run using the following arguments format: compress.py model path image path , can accept single or directory arguments
python compress.py final_model kodak/
- For decompression run using the following arguments format: decompress.py model path binary path , can accept single or directory arguments
python decompress.py final_model outputs/binary/
Traditional codecs that were developed in the past decades depended on hand crafted architectures that consisted of two main stages: Lossless and Lossy compression. First, the image is transformed to a domain that decorrelates the image components in order to increase the efficiency of the entropy coding, then an entropy model is developed to represent the image with the least amount of redundancy which corresponds to a lower Bit Per Pixel (BPP) which is used to quantify the compression ratio regardless of the visual quality of the image. The problem with the traditional codecs is that they consisted of several complex dependent modules which makes the optimization a hefty task, each module’s optimization will not contribute to the end-to-end performance as much as expected, and as the current frameworks advance through the development of a more complex modules, it makes further optimizations even harder. The recent breakthroughs in deep learning architectures paved the way to learn an end-to-end optimized framework whose development has significant difference from the traditional methods where an improvement in a module contributes to the performance in a significant way. The focus in learned compression development is the correlation of the latent code elements. Entropy models, different layer activations and objective functions are an active field of research in learned image compression.
The architecture we used is based on the one proposed in [1] with a main simplification; we omit the GAN discriminator segment of the proposed model (and subsequent training pipeline). The reasoning behind this is to reduce the model’s complexity- which poses a challenge with respect to runtime and computational resources even for the relatively small COCO dataset. We also note that the autoencoder structure alone is sufficient to produce reasonable compression with visually acceptable results for a lower computational cost. The architecture consists of three building blocks: Residual Block: Consists of two Conv2D layers each followed by a Generalized Divisive Normalization layer proposed in [3]. The GDN layer is a non-linear transformation layer with learnable parameters that aim to reduce the entropy of the responses, achieving a significantly smaller mutual information between transformed components. A skip connection is used to mitigate the problem of vanishing gradient by allowing an alternate shortcut path for gradient to flow through thus allowing the model to learn an identity function which ensures that the higher layer will perform at least as good as the lower layer, and not worse.

Non Local Attention Block: Attention modules are used to make CNN focus more on the important information rather than learning non-useful background information. The attention module consists of a simple 2D-convolutional layer, and sigmoid function at the end to generate a mask of the input feature map.
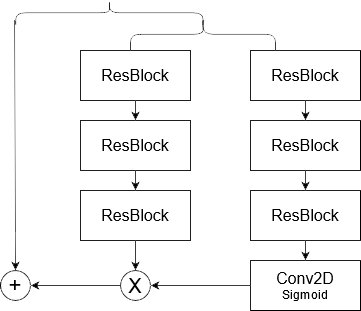
Upsampling Block: Many of the current upsampling techniques such as bicubic and transposed convolution fill the new pixels with zeros then fill them later with meaningful values. The problem with this approach is that the new values have no gradient values that can be back propagated, to avoid this problem Subpixel Convolution is used. It mainly consists of normal convolutional layers followed by a special manipulation tactic that is computationally free called pixel shuffle. This gives better results than traditional methods which are non-learnable and can only be used before or after the CNN, and better than transposed convolution due to the nonexistent gradients and computational cost. Skip connection is used to improve performance.
![]()
Pixel Shuffle, H × W × C · r² tensor to form rH × rW × C

Our model has 4 main blocks: The Encoder: Encodes the image into a latent representation. It is composed of six residual blocks, two simplified attention modules and two convolutional layers.

The Quantizer: Rounds the resultant latent code to the nearest integer to use an integer data type in order to reduce the storage footprint. Since the quantization process is non-differentiable, it cannot be used during the training phase thus it is simulated by the addition of uniformly distributed random noise from -0.5 to 0.5.
The Entropy Model: Calculates the bottleneck tensor information contents and it's trained to minimize it in order to achieve the lowest bits per pixel for the current hyperparameters[3].

The Decoder: Reconstructs the image from the quantization representations. It performs upsampling on the feature vector using subpixel convolutions. Its structure is identical to a reversed encoder where GDN transformation is inverted and upsampling blocks are used instead of downsampling.
The training then aims to minimize the loss tradeoff equation: L = λdLd(x , x̂) + λRLR(z)
Where LR is a rate loss, and Ld is the distortion loss, z is the quantized latent code, x and x̂ are the original and reconstructed images respectively, and lambdas are weights. The equation simply expresses the tricky balance between the bit-rate, distortion artifacts, and image perception and similarity.
For distortion loss we used a weighted sum of several metrics. Mean absolute error, MS-SSIM, and LPIPS loss. Traditional mean error loss produced very good color accuracy reproduction but the result was blurred due to the averaging nature of the metric. MS-SSIM loss helped improve the sharpness and the details in the textured parts of the result but it is a simple, shallow function that fails to simulate human perception. The usage of Learned Perceptual Image Patch Similarity (LPIPS) metric deep feature maps of pretrained CNN architectures proved to be an excellent perceptual metric for image reconstruction which mimics human perception better than the traditional metrics. [4]

The network was trained for 10 epochs using 256x256 images using a batch size of 8 from the training subset of the dataset. λ = 0.1. One Nvidia RTX 2080 Ti 11GB GPU was used for training, each epoch took about 1.7 hours to complete. We found no benefit from using larger images or bigger datasets. Cyclic learning rate schedule and ADAM optimizer with base LR equal to 1e-5 and a maximum LR equal to 1e-4.
As shown in the results, our results show more preservation of fine detail than BPG and don't show any blocking artifacts. Our results show that the learned compression has a promising future as we demonstrated that basic architecture results are comparable to the SOTA traditional methods. The autoencoder architecture is also capable of other tasks such as denoising and super resolution which will not result in additional computation because no extra parameters are needed. The proposed modifications to improve the results are decreasing λ to encourage further bpp reduction but this requires significantly more training iterations and examine different weights for the distortion loss components as they showed the most significant effect on results. We also recommend substituting the Leaky RELU activation function with Parametric RELU. The next planned improvements on this project are using a hyperprior entropy model in order to reduce the BPP while perserving the same quality and implementing a GAN module to enhance the reconstruction of the details
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014, September). ‘Microsoft coco: Common objects in context’. In European conference on computer vision (pp. 740-755). Springer, Cham.
Iwai, Shoma, et al. "Fidelity-Controllable Extreme Image Compression with Generative Adversarial Networks." 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2020.
J. Ballé, V. Laparra and E. Simoncelli, "Density Modeling of Images using a Generalized Normalization Transformation", in Int'l Conf on Learning Representations (ICLR), San Juan, Puerto Rico, May 2016
R. Zhang, P. Isola, A. Efros, E. Shechtman and O. Wang, "The Unreasonable Effectiveness of Deep Features as a Perceptual Metric" in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.